
So here we are in 2024 and I’m quite deep into my 4th PC build in 2 years. This one is the first one for myself. Its one of those things that I used to do every 3-5 years, but… Custom building PCs are not really useful in the world of portable computing. I have a rack now for running various equipment.

But I’m kind of building a bit of what some are calling a “boondoggle”
The Build



Spared no expense, we have the top Intel i9 CPU with an NVIDIA RTX4090 GPU running in a rack mount case. Stable diffusion running sub 10s for most prompts/models. On my buddies 4080 same prompt/model the 4090 is 30% faster. Not bad.
Noice
Operating Systems
Started out with the idea I’d run the latest Windows Server, problem here is intel is really terrible at providing NIC drivers for this OS when it isn’t “server” gear 😦 – On to install Kubuntu.
Sticking with Kubuntu for now, as it is working great and it is what I have on the PowerEdge R720. Which is a old Xeon machine I got off eBay (later)
Software Stack
Intel provides a version of python 3.9.x so that is what I’m basing my virtual environments on for local training and inference inside Jupiter notebooks. But for off-the-shelf most of the inference software suites for Stable Diffusion (Image Generation) and Large Language Models they ship with their own docker image etc.
InvokeAI
This is a great tool for local and they offer a cloud version of running Stable Diffusion or image generation. I have this running and it is quite an interesting way to explore the models.
Models
Models comes in a few flavors and are all based off of some “foundational?” model that was trained on large large datasets. Everything they generate is probably copyright grey area…
- RealVisXL_V3.0
- juggernautXL_v8RunDiffusion
These are some of the models I’ve tried out. Exited to expand into other areas of image generation but this gets us started.



Ollama
So Facebook released the original Llama model and that is kind of the standard “open” model for Large Language Models (LLMs) and Ollama Web UI provides a nice interface to it and other models.

LLama2 Runs quite well, but I am interested in largest model I can run.
I am running Mixtral24B and asking it a question based on a fictional timeline I also had it generate and I had printed to a PDF. Then I attach PDF to a new context and ask a question based on it. Quite impressive!

If you notice in the above I’m not using the wick1 system which is the RTX4090 on the Ollama Mixtral screenshot. I am using my main RTX4090 system for image generation and this other system for LLM as the performance is great even with 8 year old GPUs.
Old GPUs vs New GPUs
So as I was thinking about building a machine learning rig for the homelab, I really wanted to have a standard server for running some local development tasks and other stuff. I hit up eBay and got a R720 Dell Poweredge for $400. Not a bad system with quite the specs:
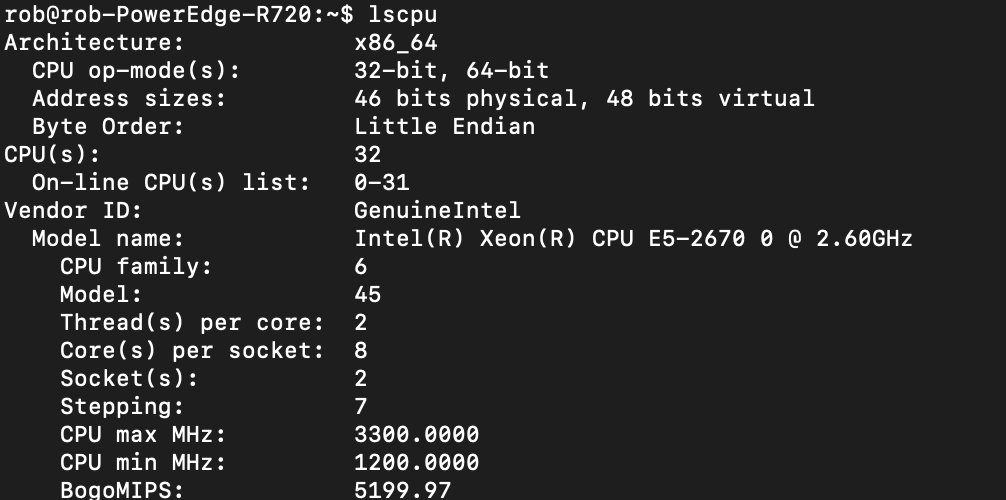
Ok this system ran fine, but what about adding some GPUs?
Look back in time to 2016 and you have the TESLA GPUs with 16-24GB RAM for less than $200. These need special cable but again easy these days.


The most shocking thing is that both GPUs work in parallel with Ollama. I think we have a 1k LLM machine!

What’s Next?
I have a chatbot in the works and trying to figure out how to pipeline and use the 3 GPUs. I have many questions about keeping models in cache and then fully integrating into a NSFW filter that is almost a requirement… Stay tuned and Happy Inferring.

One thought on “The Homelab”
Comments are closed.