
If you think programming is hard now. You are listening to the wrong gurus. Programming computers has never been easier. I will not justify that statement in a single breathe, and this is kind of a venting post, so please take with a grain of salt.
Exponential Complexity
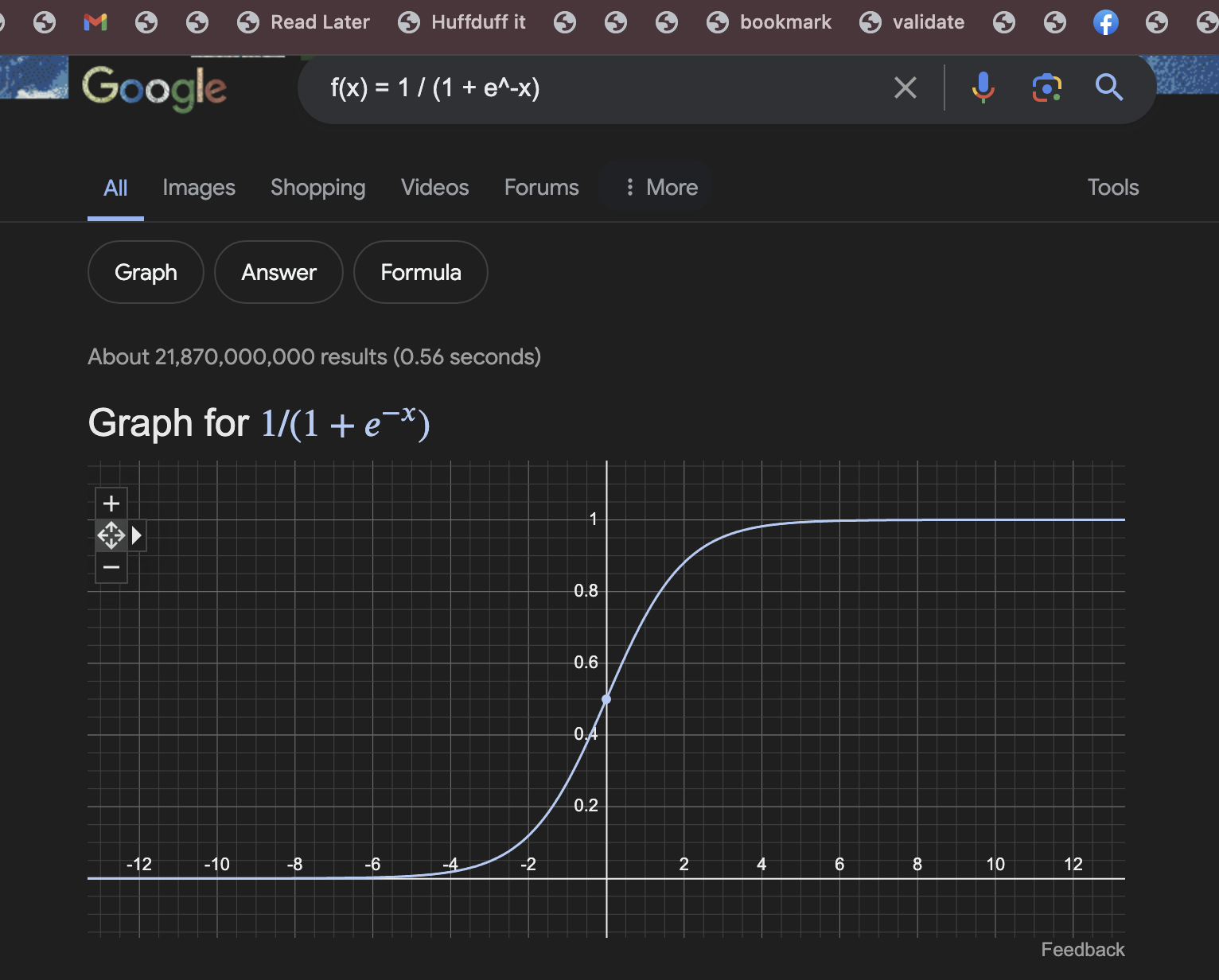
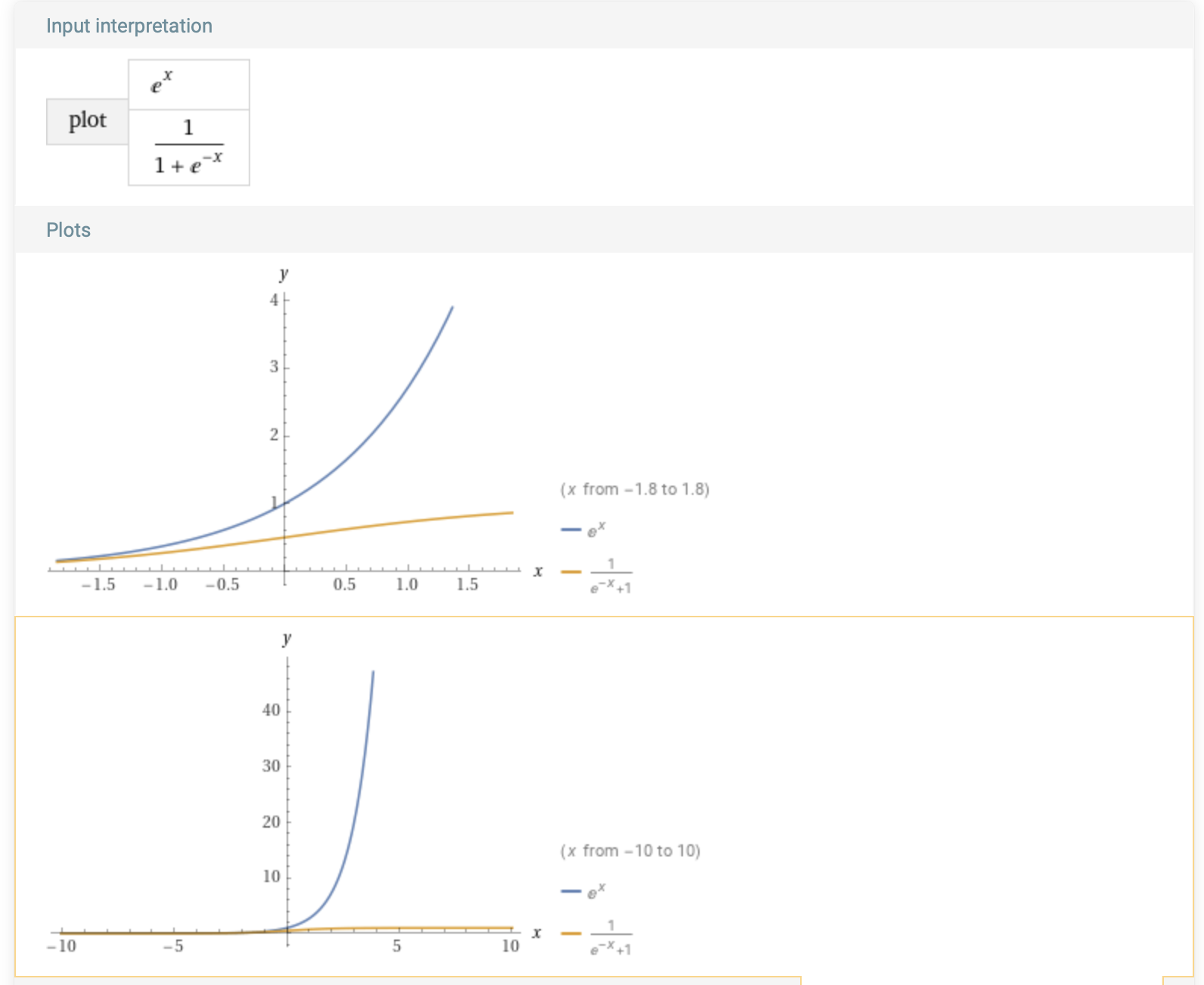
Where are we in this sigmoid? What is a sigmoid? Lets ask our AI brethren.
A sigmoid is a special type of mathematical function that is often used in machine learning and data analysis. It looks like an “S” shape, with the middle part being steep and the two ends being flat. Sigmoids have a really useful property: they can take any number as input, but they always output a value between 0 and 1.
Here’s an example of a sigmoid function:
f(x) = 1 / (1 + e^-x)This formula might look scary, but it’s actually pretty simple. The “e” in the formula is just a special number called Euler’s number (it’s about 2.71828).
The “-x” inside the parentheses means that we take the opposite of whatever number we plug in for x. So if x is 5, then -x would be -5.e^-x == 1/e^x
-rob
When we plug a negative number into this formula, we get a number very close to 0. When we plug in a positive number, we get a number very close to 1. And when we plug in zero, we get 0.5. So you can see how the sigmoid function maps any input number to a value between 0 and 1.
-Mixtral22b
Sigmoids & Friends
I ❤ functions. Sigmoids are very cool. I actually used a sigmoid back when I did my Genetic Algorithm Caterpillar thing for undergrad a decade ago. I used a slightly different but same effect.
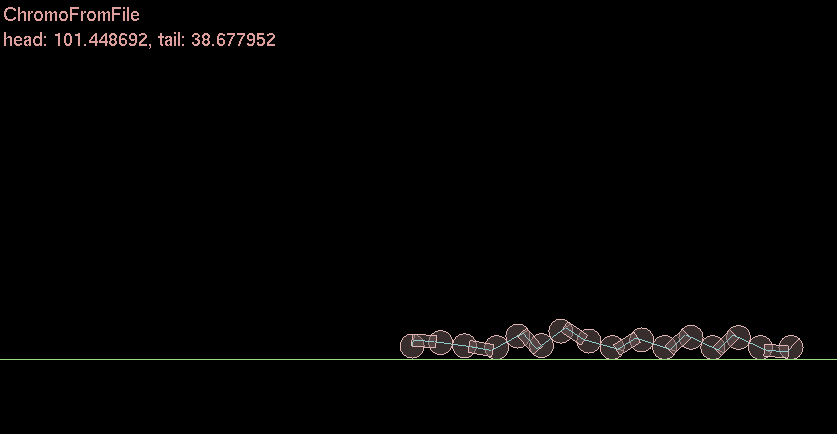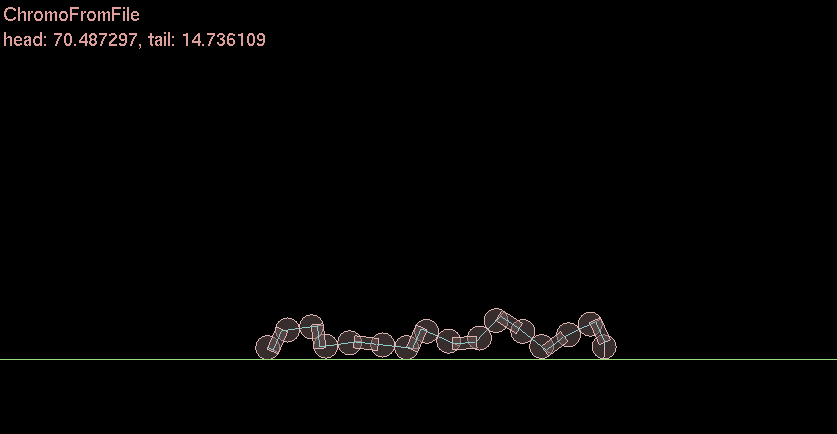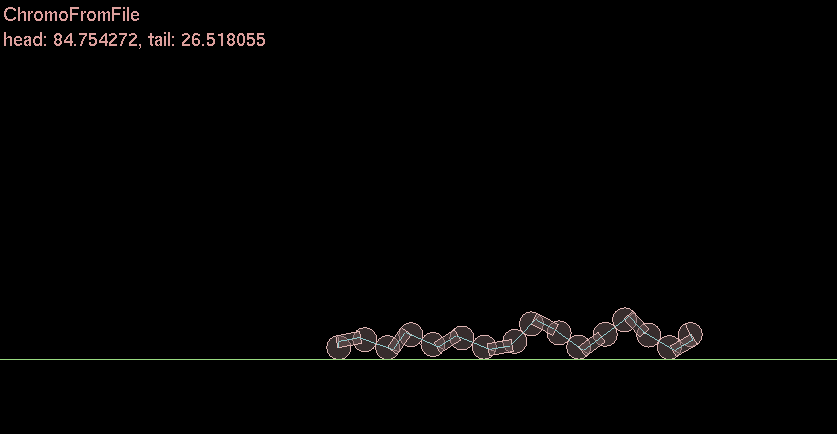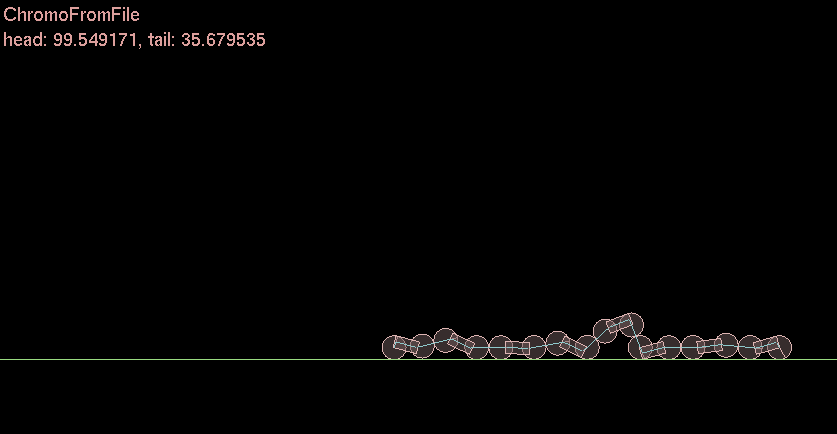

Ok so why is this useful [late update]
In neural networks in order for a neuron to become excited and “fire” the signals into the neuron through a “synapse” must be added and the fed to a sigmoid function. This will fire a zero or one to the other connected neurons. And then each layer this happens and is forward or backward propagated through the network to the output/input.
In this simple caterpillar example each joint represents a “motor” or “muscle” that is activated by the sigmoid. Zero or One. Move + Stay
So what does this have to do with the exponential complexity topic. Lets talk e^x
Put them into your graphing calculators. play around with sweep.
The Natural Number
e has this special feature. It is often called “Euler’s Number” approximately 2.718…
Deriving it links to compound interest. So you know it’s good. It is irrational meaning you cannot represent it fully with a decimal or fraction. Go take a look at your precalculus books 🙂
(e^x) != (1 / (1 + e^-x))
You can be tricked you are in an exponential function. You might be in a sigmoid 😦
Developing Now Has Never Been Easier
With the amount of documentation, tutorials, influencers, companies shilling products…. I get it. Your signal to noise ratio is approaching zero. But let me give you some signal in that numerator.
- Go back to first principles when possible (the math!!!)
- Avoid new language (versions), frameworks, fads/trends
- Unless you understand this could be completely a waste of time and you are ok with it. schedule your treks.
- Remember programming has a fashion sine curve. If you stick around long enough it will become advant-garde again 🙂
Focus on product, use your product, programmers that are NOT project/product driven are doomed to make buttons that nobody clicks. Make something so valuable and ship it that so that if it goes down, PEOPLE CARE.

