Why do drug dealers and software companies both call their customers “users”?
Not all of us have been enamored with the token spewing monster that has taken over the entire discourse around “productivity”. I’ll admit that I’ve been waffling between the idea that “it’s so over” and “we’re so back” around generative artificial intelligence (GENAI). This will be a pseudo-scientific post on my current feelings and that I really do think we are approaching the limits of our current methods.
I am thankful to the HTMX discord community which has pushed back completely on vibe coding. I still think it might have its place, but I think in this post I hopefully will lay out a few reasons why I am bearish on this topic.
Whomever is telling you to not learn to code now… don’t listen to them. I am still putting in my reps daily on https://executeprogram.com! When I first demoed “vibe coding” to my wife and I thought this was the future of coding her words brought me right back to reality. I was mouthing that ‘oh it’s trying to do this’ I’ll need to prompt it to do this instead cause I _KNOW_ better.
“Oh, this is only for people who already know how to program…”
My wife
I think it is important to note that I am a “classically trained” computer engineer. I was fortunate to do my undergraduate degree at a solid school that still taught the C programming language. This was about a decade ago and after spending many years in industry, I’m finishing up a masters degree also in engineering. This being said, my dad taught me how to program in BASIC when I was 11 years old (I’m now 42).
I learned how to program before stack overflow, and I was exposed to all the fads and trends around rapid application development (RAD) and Agile methods. Let’s just say I’m a bit surprised the current fad of vibe coding took over my lizard brain and I was enthralled.
This post is largely a penance around this hype wave I feel I added energy to. Let’s just go ahead and get started why I believe we are hitting the wall. I was waiting for this moment:
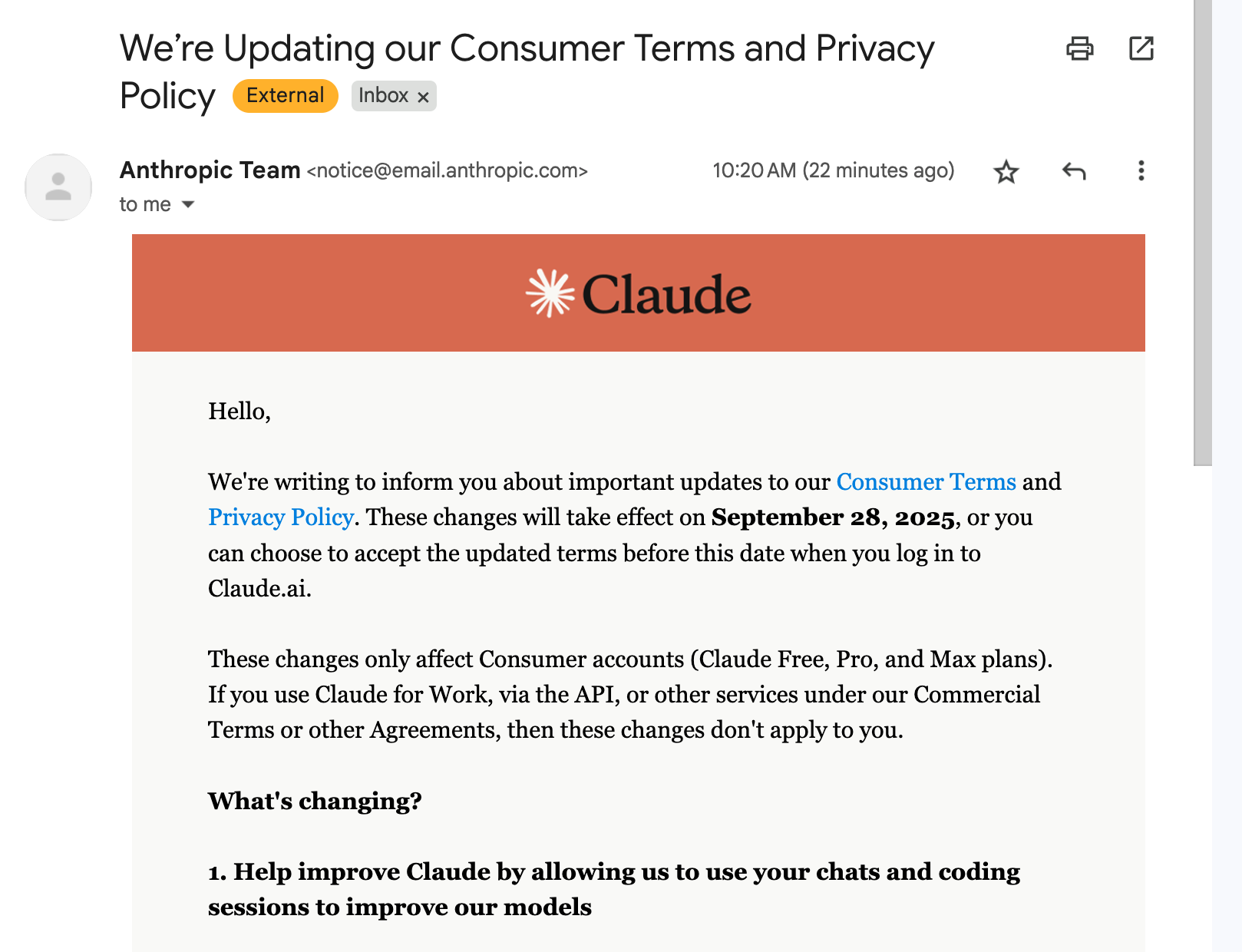
OpenAI famously only trains on your inputs/outputs to its system if you don’t pay them. Anthropic (Claude) said it never trained on your chats. I figured this was mostly a temporal thing. They could always revise their terms of service and do whatever they want. They increased their data retention policy also in this announcement to 5 years… How can they safely incorporate my chats into its training corpus!? The fact that I have to opt-out is interesting and I don’t believe everyone who clicks “agree” fully understands what this implies.
Revisiting how LLMs and Agents Work
The large unlock in the modern “Transformer” era was the fact that we could now do sequence to sequence translation for the equivalent of paragraphs of text. This is a very very hard problem and as the size of input increased it seemed impossible to scale with traditional approaches. This all changed with a simple training method of forcing the machine to predict the next word or token with a self-attention mechanism. The fact that it could translate between arbitrary domains was an incredible emergence of “intelligence”.
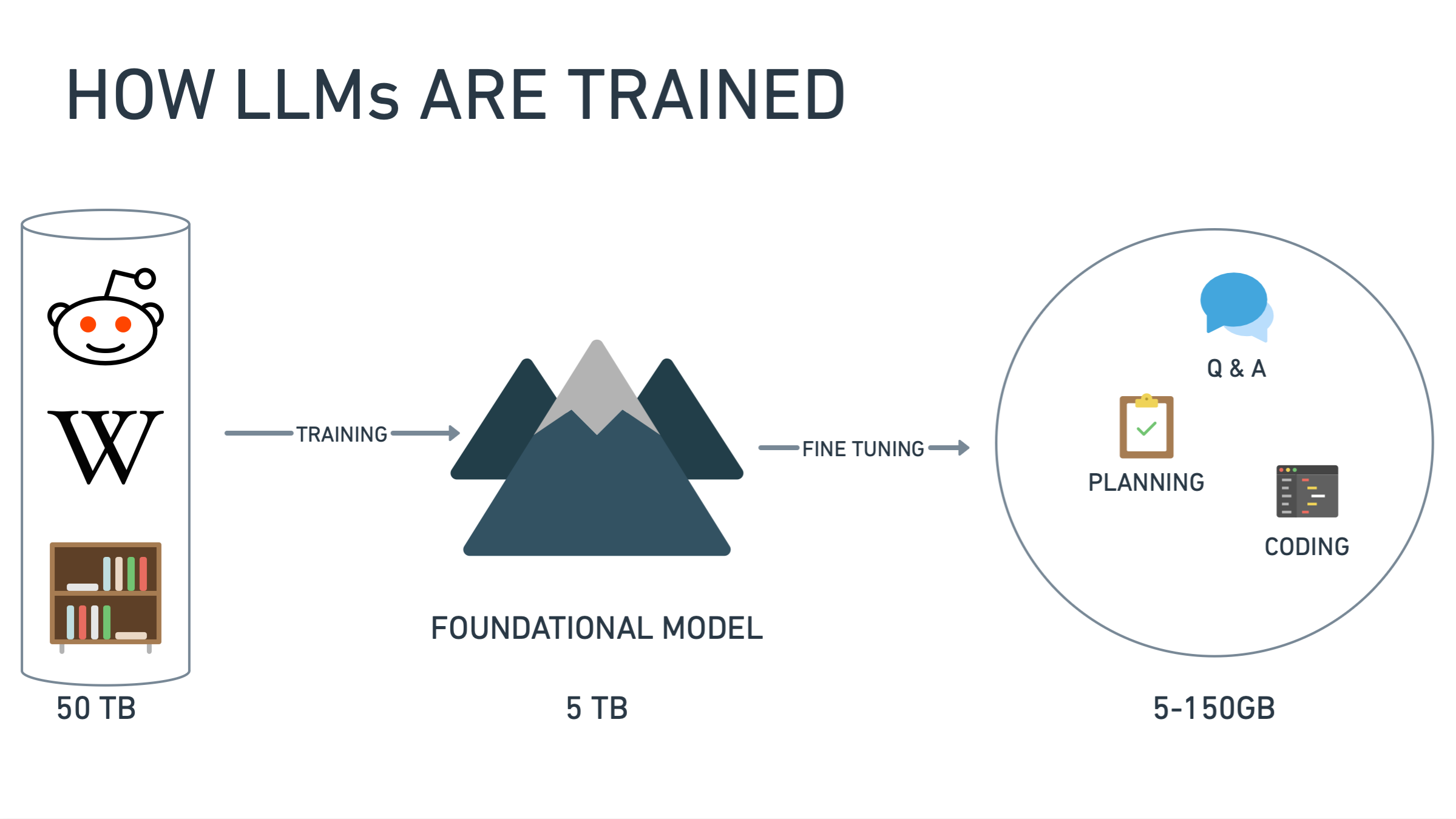
This idea of knowledge compression is great and it shows that something is definitely happening in the “latent space” between your prompt and the AI’s output. Because we are training only on language and predicting the next token or word. Let us just say this is not a thinking or reasoning being. It is a really great parlor trick. In some contexts I believe it is a net positive, but it can be detrimental in others. It is a bit Orwellian to say this is thinking or reasoning. As you can see in the video no matter what people tell you, it is just producing the next token. Perhaps between 2 <thinking></thinking> tags 🙂
So back to training on all the user data that Anthropic has been collecting… now we are going to be either doing a knowledge compression of this into the weights and biases or parameters of the model or they will be using it in the fine-tuning on using the chats as annotated datasets doing a reinforcement learning approach like the Chinese published. Or a combination of both. Who knows… Let’s just say this giant copyright infringement mixer is snowballing.
You cannot copyright anything that a large language model outputs if you don’t own the copyright to all its training corpus. It is a derivative work. This might change in the future think about how long things stay out of the public domain now? Who makes laws? Lawyers. Who likes licensing? Lawyers!
Agents as a Savior?
Setting aside the copyright issue. Because of how LLMs simply produce the next token it will happily just do that. We call it hallucinations but let’s be real, it is just doing what it has been trained to do. Produce the most likely next token.
Ok so let’s add another layer in the lasagna. I’m tired of babysitting this machine, let us write a program to do this, that is controlled by… another LLM. See a problem?
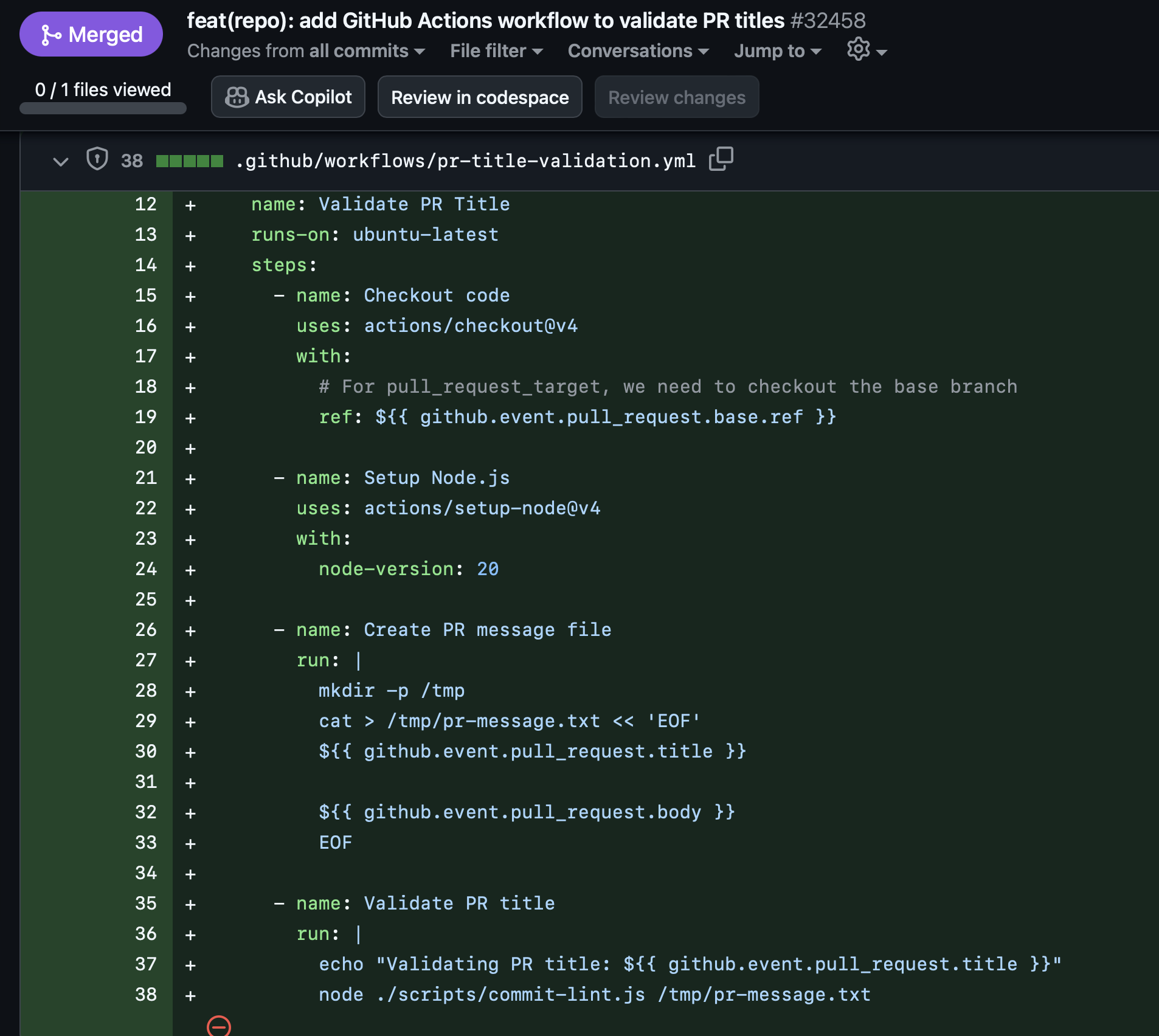
So the models seem to keep getting better, but you always seem to need a human in the loop. I was demoing something and I was sure to sandbag everything. But it still failed. I actually couldn’t figure it out on the spot. Take a gander at the screenshot below to see why it failed. Granted this is an older model but I feel we are dealing with something that is unsafe at any speed.
I will not be reading the slop, but godspeed
pop punk pelosi
Ok so in a reactive nature we will always be optimizing towards a better solution. But it will not be through anything magical, only feeding back in the failures. They have to be annotated by PEOPLE. This is why they want your chats to train on.

Context Window Non-Linearity
So this idea that it is somehow back to the prompter to add the right context and say the right words. We are right back to this idea of “programming”. The gaming of the metric around context window length… there is a non-linear quality of the results of the LLMs when the context window grows. Just because it says on the tin it has a context length of 32k tokens doesn’t mean it will produce quality output at that length. I’m actually a little bit disappointed in the meta game some of my colleagues are playing. Being stuck trying to make this context engineering machine magic work, instead of just solving the real problem. It is the bias of creating a game engine instead of creating a great game. You get stuck in this meta machine to make more machines and I’m sorry but this has never worked. It is a Ouroboros or a snake eating its own tail.

Somehow 50 years of software engineering and security practices are out the window. Running random code on your computer is dangerous. But that is what we are doing now. Its fast, fun, and dangerous. Please put your Agents in a Docker container at least. Ideally in Virtual Machine. I do like Google’s vibe coding approach with Jules.
Perception is Reality
What we feel really matters, but science doesn’t care about our feelings. I always get anecdotes from “users” and they all seem plausible but they are all based around feeling and the output that these people claim are rarely beyond a demos. Where are all the products? Also: Code is a liability, I wouldn’t brag about how large your codebase is. We need to be more grug brained.
I gain enough value from LLMs that I now deliberately consider this when picking a library—I try to stick with libraries with good stability and that are popular enough that many examples of them will have made it into the training data. I like applying the principles of boring technology—innovate on your project’s unique selling points, stick with tried and tested solutions for everything else.
Simon Willison
I feel like greenfield projects and using the LLM or agent as a cookie-cutter template is its sweet spot for value. But there have been a few studies and I think it is interesting the juxtaposition of these 2 studies:
- LLM Productivity Study: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- “Surprisingly, we find that when developers use AI tools, they take 19% longer than without—AI makes them slower.”
- “This gap between perception and reality is striking: developers expected AI to speed them up by 24%, and even after experiencing the slowdown, they still believed AI had sped them up by 20%.”
- Adderall Student Study: https://pmc.ncbi.nlm.nih.gov/articles/PMC6165228/
- “These findings indicate that healthy college students experience substantive increases in emotional and autonomic activation in the period following Adderall consumption.”
- “In summary, the present pilot study indicates that a moderate dose of Adderall has small to minimal effects on cognitive processes relevant to academic enhancement (i.e., on reading comprehension, fluency, cognitive functioning), in contrast with its significant, large effects on activated positive emotion…”
- https://www.netflix.com/title/80117831
In both cases the people who have the active part of the experiment rather than the placebo “feel” like it is working… I do feel like the coding study is flawed because of the “warm-up” time it takes to learn how to prompt correctly etc. Also vibe coding excels at greenfield projects. I don’t think anyone can argue that vibe coding demos and MVPs won’t be faster upfront especially if you have little experience with the frameworks and platforms. But what happens when you have to actually depend on the slop?
It is fascinating to read about someone who is doing real science with NLP states what it takes to really “improve” your responses is jaw-dropping. 1000 annotated samples to prove 1% increase. No wonder Anthropic needs all our personal chat logs…
Why are we hitting a wall? Models can’t get any bigger, we can’t really train them and retain the information in the training because of something, something scaling laws:
As a result, raising their reliability to meet the standards of scientific inquiry is intractable by any reasonable measure. We argue that the very mechanism which fuels much of the learning power of LLMs, namely the ability to generate non-Gaussian output distributions from Gaussian input ones, might well be at the roots of their propensity to produce error pileup, ensuing information catastrophes and degenerative AI behaviour.
DRAFT NOTICE

I am appreciative of your feedback and suggestions for fixing this article.
What was the point of all this? Why is there a limit? If we have to go say the magic words correctly to get the Agent to respond properly AND we also have to double check it. What is the point? Aren’t we just programming again?
Further Reading
https://en.wikipedia.org/wiki/Gell-Mann_amnesia_effect
https://blog.langchain.com/context-engineering-for-agents/
https://arxiv.org/abs/2506.02153
Security Tangent
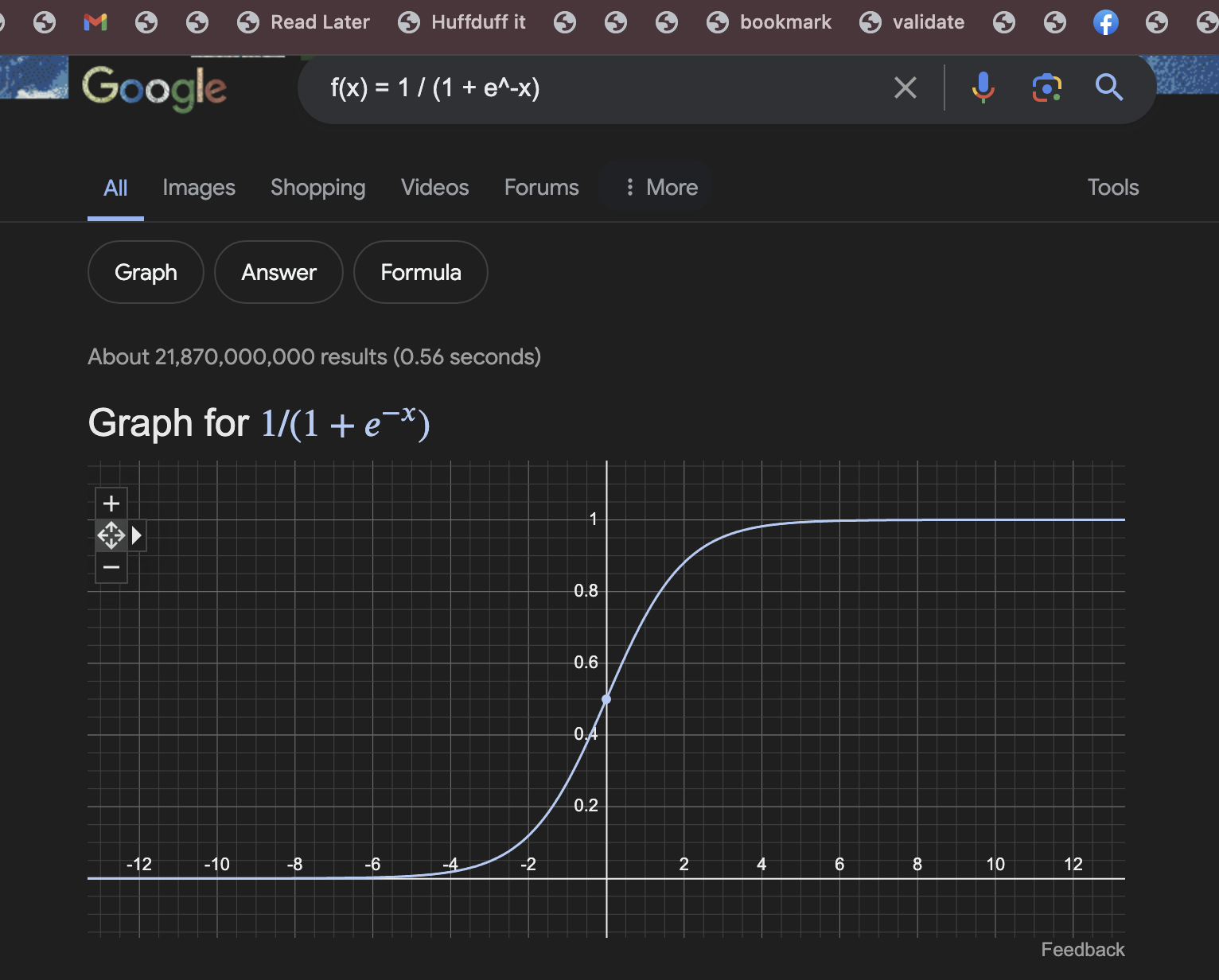
Great breakdown of this new vector of attack. Unescaped user input (PR Title) injection to arbitrary code execution in the build system that lead 10k develops poisoned at the well:
https://www.kaspersky.com/blog/nx-build-s1ngularity-supply-chain-attack/54223/