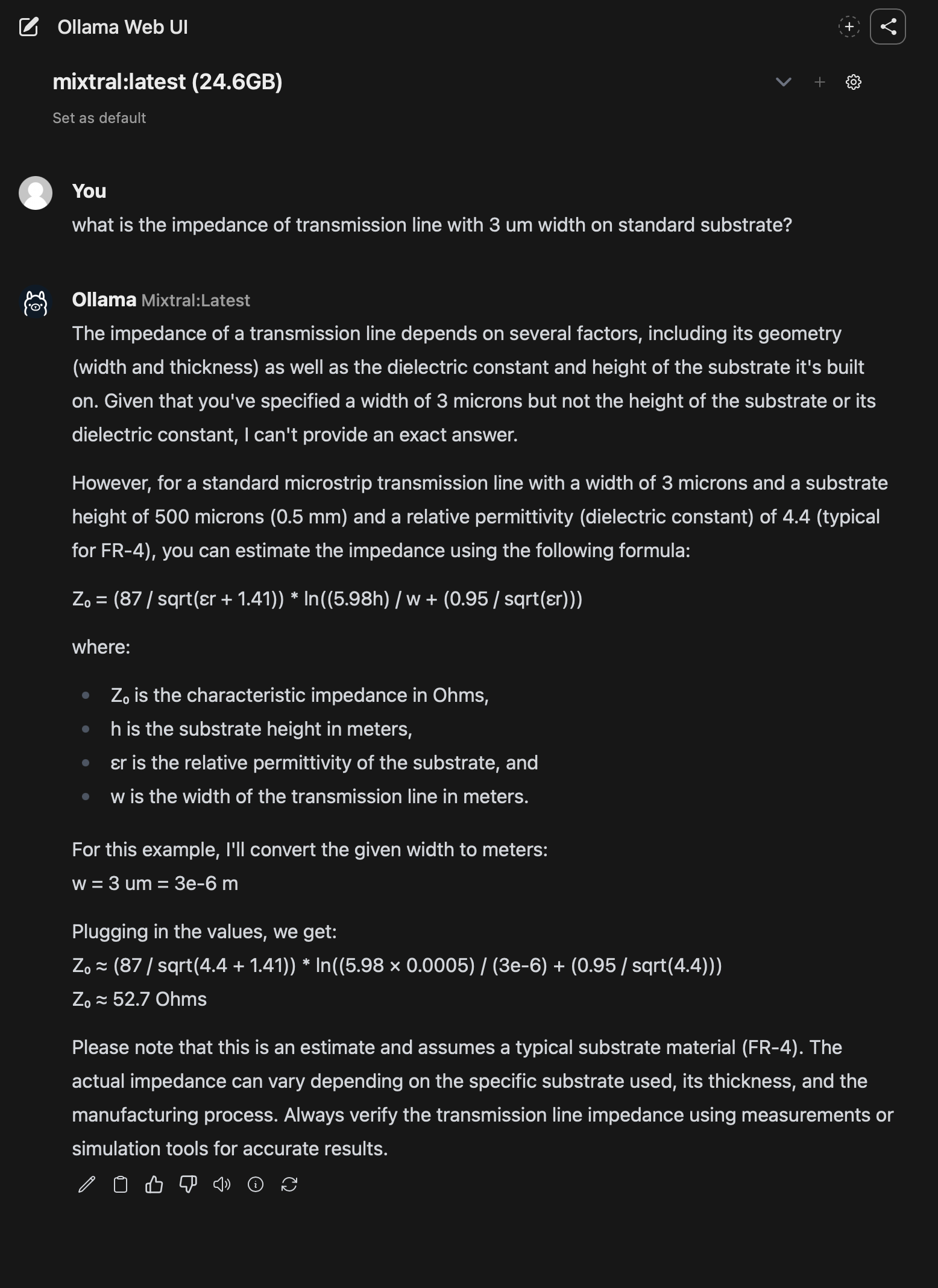
It is honestly a question I ask myself often as I’m approaching the last 2 semesters of my own journey.
Maybe take a step back and think about your educational arc.

Why do a Bachelors Degree?
So you can get a good job and make some money! Most engineering jobs at large companies and governments require it. I made 60k when I got out of college. My highest paying job before that was 60+ hour weeks running a kitchen for 40k. Your mileage may vary and I was hired in the Gold Rush of tech. I feel for you people trying to get jobs now.
Why do engineering?
If you want to know how things are built, study engineering. It will force you to learn all the math you care to ever learn. Then you will be forced to apply it. This is the critical stage. Going back to your fundamentals and organize your thoughts. Hammock Time. Optimize for your particular problem, solving for a trade-off. It is how shit gets done. Da Vinci was an engineer as well as an artist. Who doesn’t want to be Da Vinci?
Wait I have to take 5 years of Math?
Yes. Next question. It’s why you should be homeschooled. You could get to calc def by 8th grade if you had private tutor and no schedule from kindergarten.
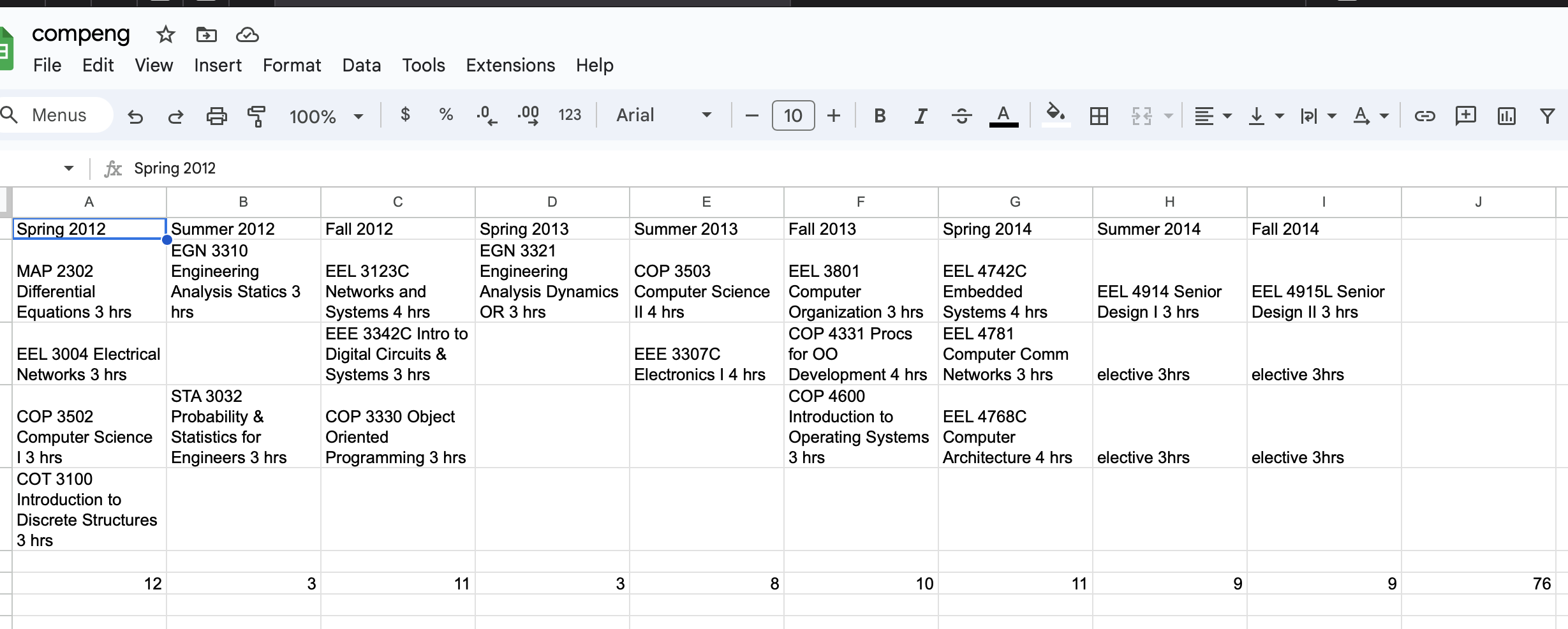
Wait it takes 5 years for me to get Bachelors Degree?
Yes. If you start in Intermediate Algebra like I did. It was worth it to take them semester after semester. Algebra, Trig, Pre-Calc, Calculus I-III, Differential Equations, Linear Algebra, Discrete Math, Computer Science 2 is essentially a math class as well as all your circuit classes, statics, dynamics…
Ok I am done with this format I think. Back to original question. Why Masters? Because as you get to the end of bachelors that is when all the interesting stuff happens. You finally got through the math to unlock the classes that you find interesting
- Programming Language Design
- Artificial Intelligence
- Robotics
- Databases
- 3D Graphics
- Advanced Data Structures
- Parallel Computing
- …
By this time you are already quite burned out and you just need to get done with your 5 year tour and get a job and start putting money in the bank and pay off the student debts. But let’s talk about the content of these classes that are “new” in the sense that calculus and the laws of motion are hundreds of years old. We are talking things invented or commercialized in the last 50ish years.
The content of these classes that are “soft” on science I would say and more on applied engineering. They can be a mixed bag. It often feels wrong while you are in the class if you are in the know.
Let’s talk about AI at the University of Central Florida in the early 2010s. Dr. Gomez taught the class. It was cool class. But he basically taught us LISP for first month of class. He was Natural Language Processing (NLP) guy that adored Minsky and had professional acquiantance with him as far as he said.
But to ignore neural networks in an artificial intelligence class in 2014 is kind of bonkers. To use LISP. I am glad I learned it, but this class was stuck right there in 1980. NLP was moving quickly to statistical methods rather than formal grammars. But we learned CDR and how to really run code in our heads with our Mind Compiler for LISP. Oatmeal and Fingernail Clippings (())()())

<clipped>
Overall, while Minsky’s NLP techniques were innovative and influential in their time, they have largely been superseded by modern statistical and machine learning approaches. However, some of the ideas behind dynamic predictive analysis are still used in some NLP systems today, and the focus on parallelism and efficiency remains relevant in the context of modern computing architectures.
Mixtral24b
Minsky famously shit all over the perceptron and killed neural network public opinion for 20 years cause he said it couldn’t learn XOR. He used one neuron. Da Vinci Garfield doesn’t like this.

Ok so why go get masters?
I wanted to finally take all the courses I missed in undergrad.
- Machine Learning (was lame unfortunately, I’m replacing it with Andrew Ng’s coursera series 2.5/5 done)
- Digital Signal Processing (recommend)
- Aerial Robotics
- Arm Robotics
- Very Large Scale Integration VSLI (bucket list!)
- Power Electronics
- Advance Applied Differential Equations and Friends (hardest math class yet, Matlab is star)
Never stop learning. Most of the learning is done in addition to classroom. It is a framework that you build out with your individual efforts.
There is also something to be said about networking and meeting new people and hearing new ideas. The University is a special place.