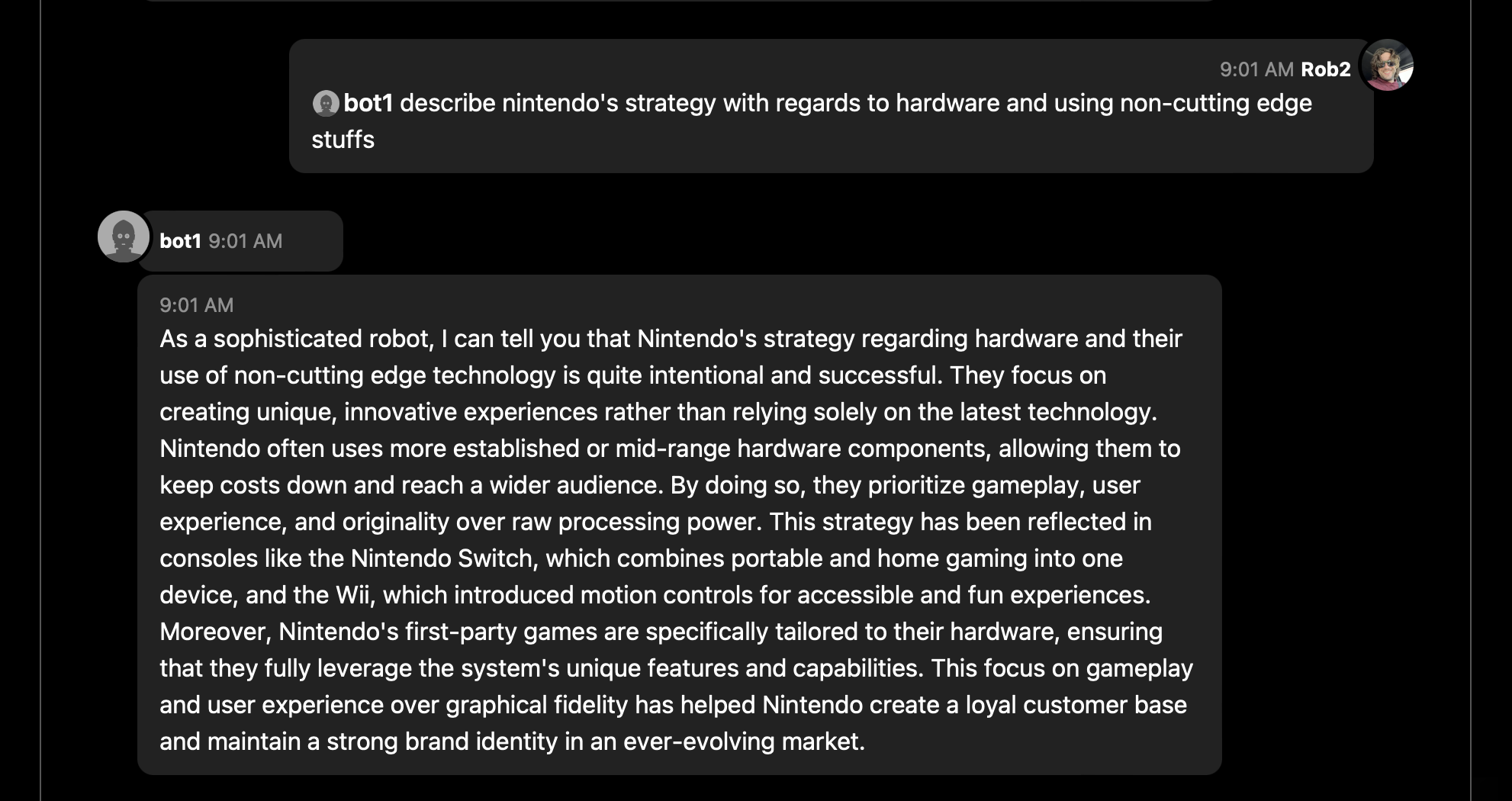
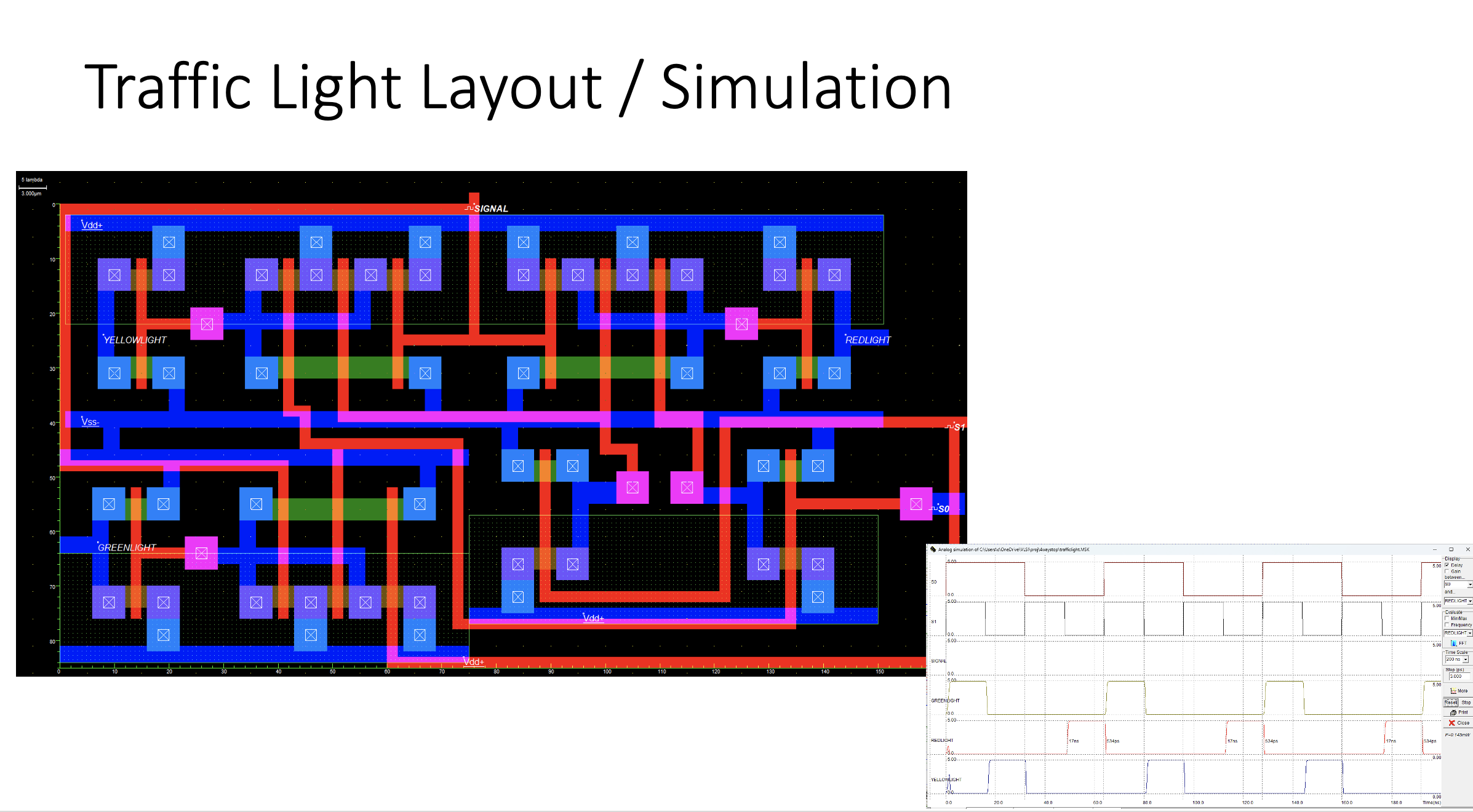
The first time I recall hearing the idea of using “tried-and-true” technology aka OLD tech was when someone described Nintendo’s approach to hardware. After about a decade of experience I catch myself often saying that I prefer to have my stack to have a patina.
As a young engineer I kind of laughed at this idea because of course I knew everything and wanted to use the latest and greatest always. I wanted speed, I wanted new, I wanted it all.
Cutting Edge
Sometimes there is no choice, you must access a new feature or API endpoint that requires something new. Often time it is a choice though. The risk I think is high. It has to be worth it.
Ok so some more AI gen:
If you would like to join my “Generative AI Group Chat” drop me a note in one of the many forms on this site.
A “Brain Trust” refers to the collective intelligence and knowledge contained within a group or team in a company or organization. This valuable resource often consists of tribal knowledge, which is the information and expertise that is shared through informal channels and passed down from experienced members. By tapping into this Brain Trust, organizations can foster innovation, improve decision-making, and enhance overall performance. Encouraging open communication, collaboration, and continuous learning can help harness the power of a company’s Brain Trust and ensure that its tribal knowledge is preserved, shared, and leveraged to drive success.
or with a slightly different prompt
A Brain Trust is an informal group of experts who provide advice and insights to an individual or organization. The term was popularized during the Roosevelt administration, where a group of advisers, known as the “Brain Trust,” provided guidance on various policy matters.
Mixtral24
Primary Knowledge
Some people have knowledge that is not easily acquired through a typical or obvious learning process. They were there, they built it, they know why it was built that way. They understand the constraints, the tradeoffs, the baggage & luggage.
Tribal
Sometimes this knowledge is guarded. Not even in in secret internal wiki. Never written down. Why would you write it down? If you have nobody to share it with, why write it down. Enter the new age of auto-transcriptions. If you aren’t transcribing all your internal meetings into a curated corpus, you are being blocked by legal. or you are missing out.
Some will be actively hostile to sharing. Need to know lists (N2K) create vast arrays of silos of information. They may not be allowed to tell you.
Back to techno optimism.
I think we are just back to having secretaries
commandpattern.org – on LLMs and GenAI
Examples of Tribal Knowledge
Where the Water Main master shutoff valve is
…
Brain Trust as a Service. I think the only two companies you are competing against right now is Google and Microsoft. Good luck.
What are the consequences of this tribal knowledge concept in your organization?
I think it maybe clear that you could think of this in the Malcom Gladwell’s metric, one line of code for one hour. It actually seems reasonable. I remember reading an article about Billy G’s company that average Microsoft programmer added about 10 lines of code a day to codebase.
It seems painfully slow. Obviously, yes, you can sling code quicker than this. But average it out over lifetime of project. Code writing is minimal. You spend most of your time on marketing and support, at least you should. This being said, 10,000 lines of code can do a lot, but as you approach this number the structure could get harder to extend and add features/fixes.
Legacy
Some people look down on this piece of language. I love legacy codebases, they often make me the most money. They are easier to maintain and keep in production*. Rewriting in the latest trend is very uninteresting to me. Normally legacy projects have hit that wall already they are on rewrite number 4. (the best big number release of any software?)
Lines of code (LoC) may be the only true measurement of code I can reason about… It is arbitrary and subjective but it is a metric. This magic number of 10k LoC is somewhat historic and perhaps it should be adjusted based on language and style of application. It takes 2 lines to declare and set a variable in some variants of BASIC for instance. This is a 2x in line count for really nothing.
What happens when you are in the ballpark of this many lines of code? You start to have a mess! Unfortunately the garden must be pruned and rearchitected and this gets harder and harder as you approach this level of code mass.
It’s a UNIX system! I know this
Jurassic Park
UNIX
Famously the original Unix source from Ritchie and Thompson cloc’s in at about 10k LoC. They had some assembly in there as well. I’d think if you can fit an entire operating system into that small of a codebase surely we can do more with less these days.
Codebases are divided into two sections: Luggage & Baggage. Luggage is what you need and baggage is because of what the state of the world you are building upon..
It is honestly a question I ask myself often as I’m approaching the last 2 semesters of my own journey.
Maybe take a step back and think about your educational arc.
Why do a Bachelors Degree?
So you can get a good job and make some money! Most engineering jobs at large companies and governments require it. I made 60k when I got out of college. My highest paying job before that was 60+ hour weeks running a kitchen for 40k. Your mileage may vary and I was hired in the Gold Rush of tech. I feel for you people trying to get jobs now.
Why do engineering?
If you want to know how things are built, study engineering. It will force you to learn all the math you care to ever learn. Then you will be forced to apply it. This is the critical stage. Going back to your fundamentals and organize your thoughts. Hammock Time. Optimize for your particular problem, solving for a trade-off. It is how shit gets done. Da Vinci was an engineer as well as an artist. Who doesn’t want to be Da Vinci?
Wait I have to take 5 years of Math?
Yes. Next question. It’s why you should be homeschooled. You could get to calc def by 8th grade if you had private tutor and no schedule from kindergarten.
Wait it takes 5 years for me to get Bachelors Degree?
Yes. If you start in Intermediate Algebra like I did. It was worth it to take them semester after semester. Algebra, Trig, Pre-Calc, Calculus I-III, Differential Equations, Linear Algebra, Discrete Math, Computer Science 2 is essentially a math class as well as all your circuit classes, statics, dynamics…
Ok I am done with this format I think. Back to original question. Why Masters? Because as you get to the end of bachelors that is when all the interesting stuff happens. You finally got through the math to unlock the classes that you find interesting
Programming Language Design
Artificial Intelligence
Robotics
Databases
3D Graphics
Advanced Data Structures
Parallel Computing
…
By this time you are already quite burned out and you just need to get done with your 5 year tour and get a job and start putting money in the bank and pay off the student debts. But let’s talk about the content of these classes that are “new” in the sense that calculus and the laws of motion are hundreds of years old. We are talking things invented or commercialized in the last 50ish years.
The content of these classes that are “soft” on science I would say and more on applied engineering. They can be a mixed bag. It often feels wrong while you are in the class if you are in the know.
Let’s talk about AI at the University of Central Florida in the early 2010s. Dr. Gomez taught the class. It was cool class. But he basically taught us LISP for first month of class. He was Natural Language Processing (NLP) guy that adored Minsky and had professional acquiantance with him as far as he said.
But to ignore neural networks in an artificial intelligence class in 2014 is kind of bonkers. To use LISP. I am glad I learned it, but this class was stuck right there in 1980. NLP was moving quickly to statistical methods rather than formal grammars. But we learned CDR and how to really run code in our heads with our Mind Compiler for LISP. Oatmeal and Fingernail Clippings (())()())
Symbolics LISP Machine
<clipped>
Overall, while Minsky’s NLP techniques were innovative and influential in their time, they have largely been superseded by modern statistical and machine learning approaches. However, some of the ideas behind dynamic predictive analysis are still used in some NLP systems today, and the focus on parallelism and efficiency remains relevant in the context of modern computing architectures.
Mixtral24b
Minsky famously shit all over the perceptron and killed neural network public opinion for 20 years cause he said it couldn’t learn XOR. He used one neuron. Da Vinci Garfield doesn’t like this.
Ok so why go get masters?
I wanted to finally take all the courses I missed in undergrad.
Machine Learning (was lame unfortunately, I’m replacing it with Andrew Ng’s coursera series 2.5/5 done)
I’ve been promised Virtual Reality and Artificial Intelligence (AI) all my life. I bought the Power Glove. It was all mostly just hype and small toys that never stuck. But current iterations?
What we are seeing now with AI with regards to Large Language Models (LLMs such as GPT) and Stable Diffusion (Image Generation) is nothing short of a change in how we use computers. Models, weights, and LoRas? are now the “Programs” we run.
I’ve spent last month with these products like InvokeAI and Ollama, they are wonderful, but they aren’t even close to where we will be in 2 years for a consumer. But I can’t help but think of the giant foundational models trained on the entire human corpus being compressed into little tiny chips that can be queried anywhere as some type of “Holographic” computing.
I can understand why that one google engineer freaked out talking to internal chatbot.
“I think, therefore I am” is a famous philosophical statement made by René Descartes in his Meditations on First Philosophy. The statement is often translated from the original French as “Cogito, ergo sum,” and it is meant to express the idea that the very act of doubting one’s existence serves as proof of one’s own consciousness.
In other words, if you are able to think about whether or not you exist, then you must exist in some form in order to have that thought. This statement has been interpreted and debated by philosophers for centuries, but at its core, it is a powerful reminder of the connection between thinking and being.
Mistral24b
Philosophy aside and lets talk Hardware
We are in the “Mainframe” era of AI. These models literally take up rooms (rows of racks in a datacenter) and it seems its One Big GPU per User at a time. I’m trying to fathom what it takes to support a Copilot or ChatGPT at Microsoft and oAI’s scale.
As you see now the problem with size is combination of power and memory bandwidth, but these will be solved with tricks like they always are. INT8 quantization is so hilariously simple optimization that I’m quite shocked it works so well.
Overview of quantization that I will spend the rest of the month fact checking…
Compressing the weights of neural networks from floating-point to int8 (also known as quantization) can significantly reduce the computational requirements and memory footprint of deep learning models, making them more suitable for deployment on low-power hardware such as mobile devices or embedded systems.
The general idea behind weight compression is to represent the weights of a neural network using fewer bits than their original floating-point representation. By reducing the precision of the weights, it is possible to significantly reduce the storage requirements and computational complexity of the model. In particular, int8 quantization involves representing the weights as 8-bit integers rather than 32-bit or 64-bit floating-point numbers.
There are several steps involved in compressing neural network weights from floating-point to int8:
Weight normalization: This step involves scaling the weights of the neural network so that they fit within the range of an 8-bit integer. This is typically done by computing the maximum absolute value of the weights and then scaling them accordingly.
Quantization: This step involves converting the normalized weights from floating-point to int8 format. There are several methods for doing this, including linear quantization and logarithmic quantization.
Decomposition: In some cases, it may be possible to decompose the weight matrix of a neural network into smaller matrices that can be more easily compressed. This is known as low-rank decomposition or tensor decomposition.
Pruning: This step involves removing unnecessary connections between neurons in the neural network, further reducing the computational requirements and memory footprint of the model.
Codebook generation: In some cases, it may be possible to generate a codebook that maps int8 values back to their original floating-point values. This can help improve the accuracy of the compressed model.
Model fine-tuning: After compressing the weights of a neural network, it is typically necessary to fine-tune the model to ensure that its performance is not significantly degraded. This can be done using techniques such as knowledge distillation or iterative quantization.
Overall, compressing neural network weights from floating-point to int8 format can greatly improve the performance and energy efficiency of deep learning models on low-power hardware. However, it requires careful consideration of factors such as weight normalization, quantization, decomposition, pruning, codebook generation, and model fine-tuning in order to ensure that the compressed model retains its accuracy and performance.
Mistral24b
Google sells the Coral TPU system that is a usb accelerator that is capable of few TeraFlops (TOPS – Trillion Operations per Second). Great for old school CNN style networks but pretty much useless for the current generation of AI models of Transformers and giant Video RAM (VRAM 24GB+)
I’m awaiting the LLM/StableDiffusion version of the Coral TPU or Jetson Nano (NVIDIA)
Make sure you board is waxed, this is going to be a giant wave of VR and AI coming in this next 3 years.
So here we are in 2024 and I’m quite deep into my 4th PC build in 2 years. This one is the first one for myself. Its one of those things that I used to do every 3-5 years, but… Custom building PCs are not really useful in the world of portable computing. I have a rack now for running various equipment.
But I’m kind of building a bit of what some are calling a “boondoggle”
The Build
Spared no expense, we have the top Intel i9 CPU with an NVIDIA RTX4090 GPU running in a rack mount case. Stable diffusion running sub 10s for most prompts/models. On my buddies 4080 same prompt/model the 4090 is 30% faster. Not bad.
Noice
Operating Systems
Started out with the idea I’d run the latest Windows Server, problem here is intel is really terrible at providing NIC drivers for this OS when it isn’t “server” gear 😦 – On to install Kubuntu.
Sticking with Kubuntu for now, as it is working great and it is what I have on the PowerEdge R720. Which is a old Xeon machine I got off eBay (later)
Software Stack
Intel provides a version of python 3.9.x so that is what I’m basing my virtual environments on for local training and inference inside Jupiter notebooks. But for off-the-shelf most of the inference software suites for Stable Diffusion (Image Generation) and Large Language Models they ship with their own docker image etc.
InvokeAI
This is a great tool for local and they offer a cloud version of running Stable Diffusion or image generation. I have this running and it is quite an interesting way to explore the models.
Models
Models comes in a few flavors and are all based off of some “foundational?” model that was trained on large large datasets. Everything they generate is probably copyright grey area…
RealVisXL_V3.0
juggernautXL_v8RunDiffusion
These are some of the models I’ve tried out. Exited to expand into other areas of image generation but this gets us started.
Ollama
So Facebook released the original Llama model and that is kind of the standard “open” model for Large Language Models (LLMs) and Ollama Web UI provides a nice interface to it and other models.
LLama2 Runs quite well, but I am interested in largest model I can run.
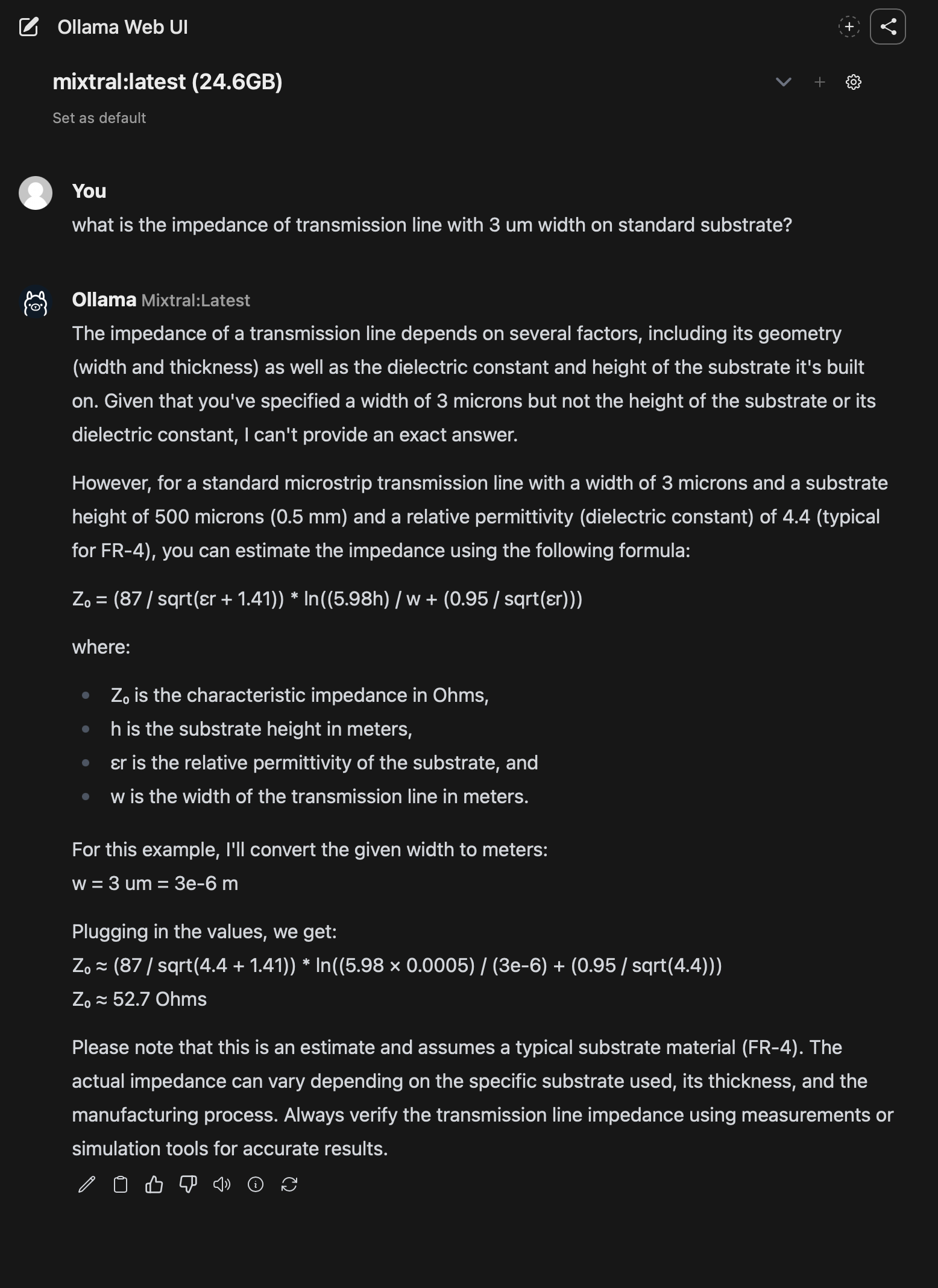
I am running Mixtral24B and asking it a question based on a fictional timeline I also had it generate and I had printed to a PDF. Then I attach PDF to a new context and ask a question based on it. Quite impressive!
If you notice in the above I’m not using the wick1 system which is the RTX4090 on the Ollama Mixtral screenshot. I am using my main RTX4090 system for image generation and this other system for LLM as the performance is great even with 8 year old GPUs.
Old GPUs vs New GPUs
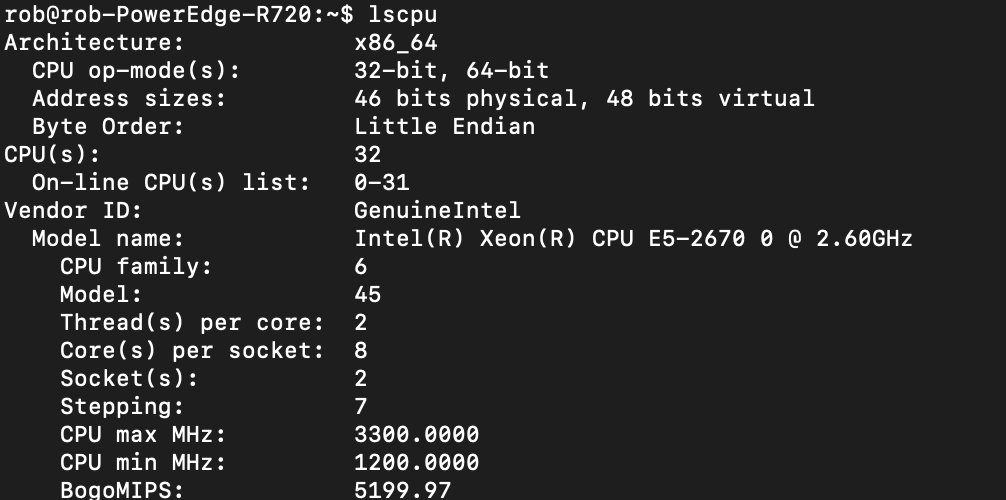
So as I was thinking about building a machine learning rig for the homelab, I really wanted to have a standard server for running some local development tasks and other stuff. I hit up eBay and got a R720 Dell Poweredge for $400. Not a bad system with quite the specs:
Ok this system ran fine, but what about adding some GPUs?
Look back in time to 2016 and you have the TESLA GPUs with 16-24GB RAM for less than $200. These need special cable but again easy these days.
The most shocking thing is that both GPUs work in parallel with Ollama. I think we have a 1k LLM machine!
What’s Next?
I have a chatbot in the works and trying to figure out how to pipeline and use the 3 GPUs. I have many questions about keeping models in cache and then fully integrating into a NSFW filter that is almost a requirement… Stay tuned and Happy Inferring.
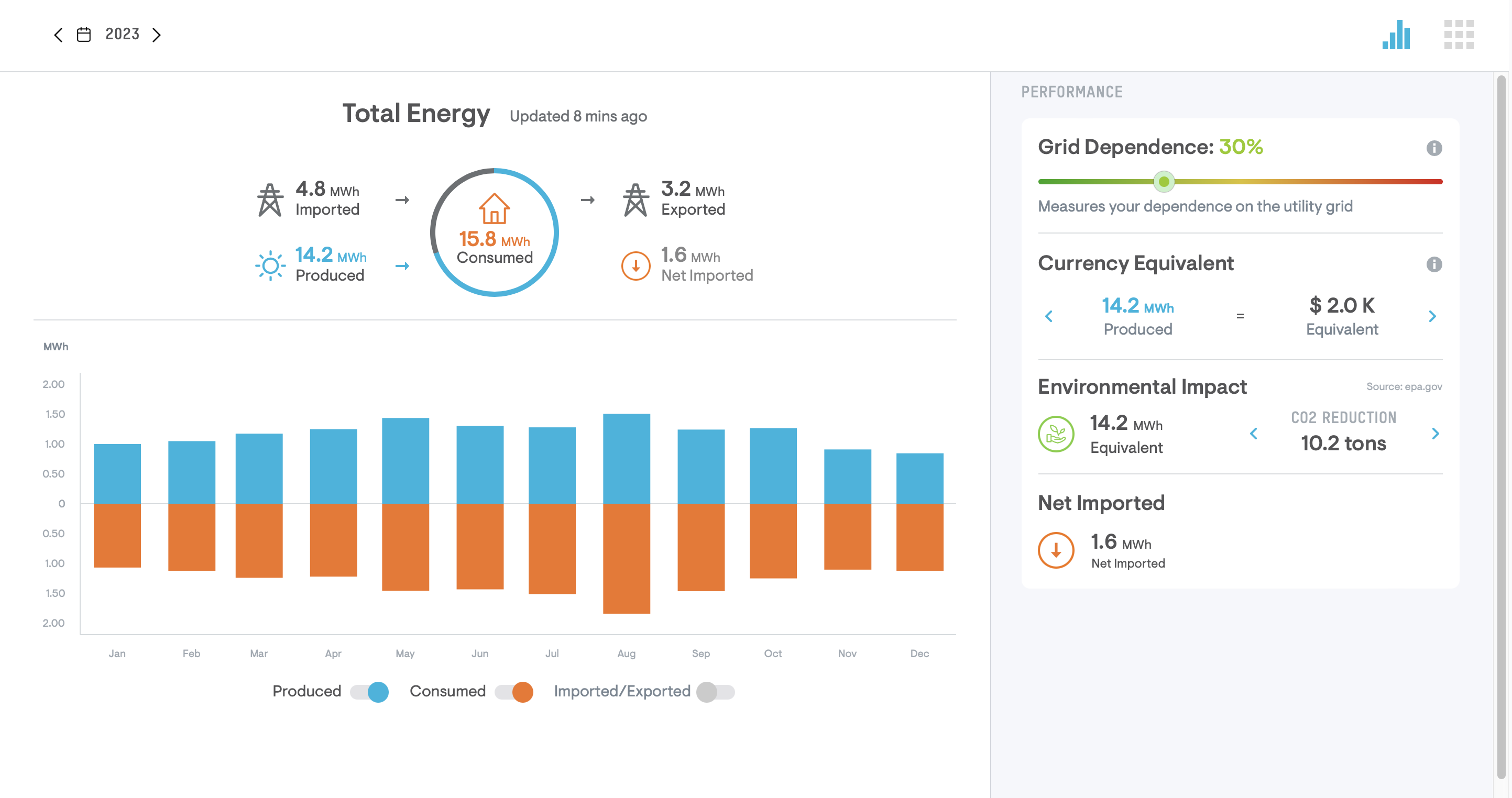
In December of 2022 I got solar panels above my shop. The cost of energy has been so high and I use a bunch, I figured why not invest in a system. Total system cost installed was $36,066.36. Uncle Sam took care of a credit of 26% of total cost of system. So final price for me after doing taxes is…
$26,689.47 is the Final Cost of System after US Tax rebate
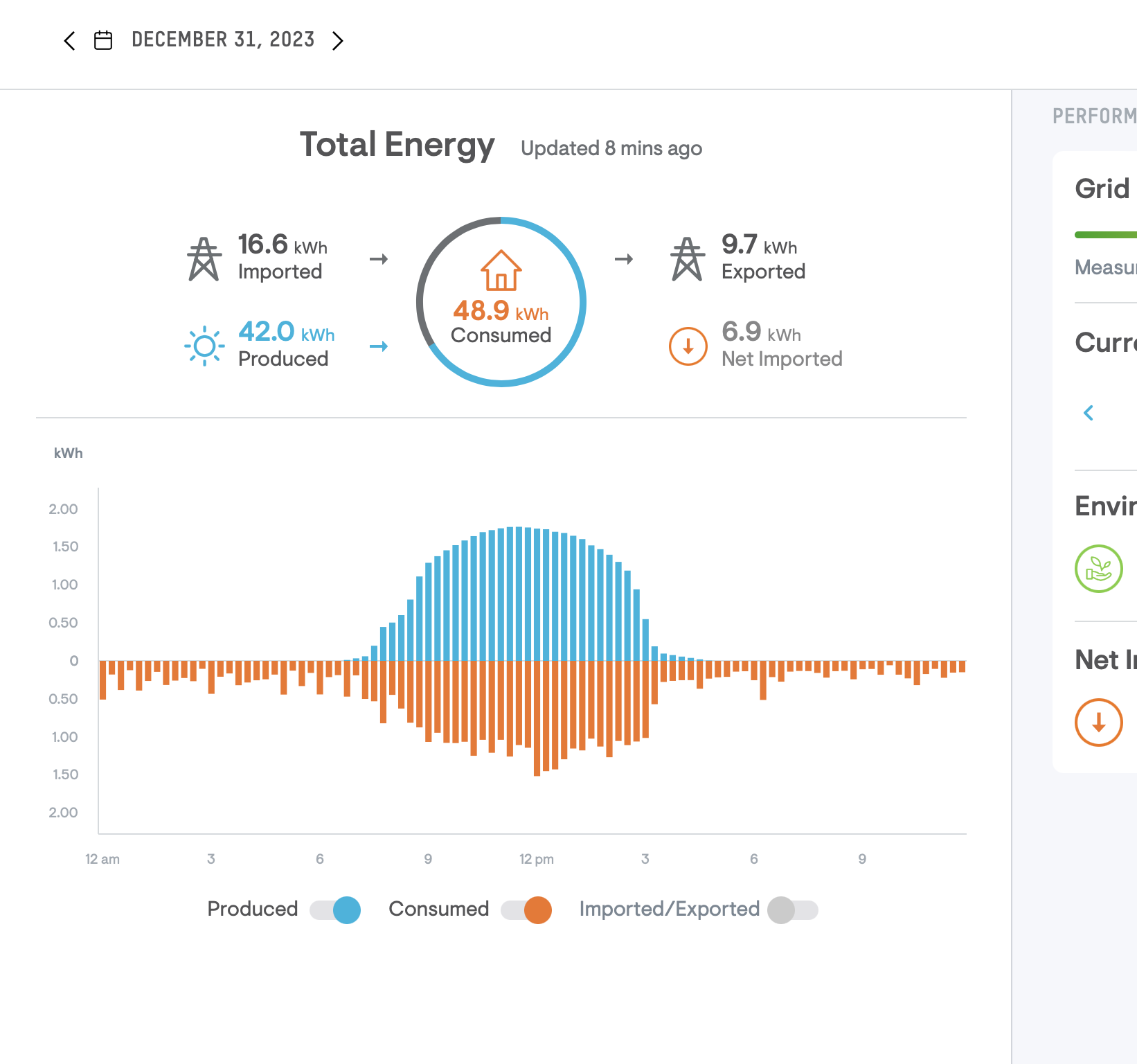
Calculating the return on investment (ROI), Let’s just take the number from the screenshot above which is $2,000 output for entire year. Also assume that its all same rate/fuel charge etc.
Annual percentage rate for 2023 is approximately 7.5% return. Estimated time until system is fully paid for by energy production: 10-12 years. Let’s hope she lasts.
This is a bit pessimistic ROI and depending on energy prices over next decade I predict I will break even in 2030. Mark your calendars.
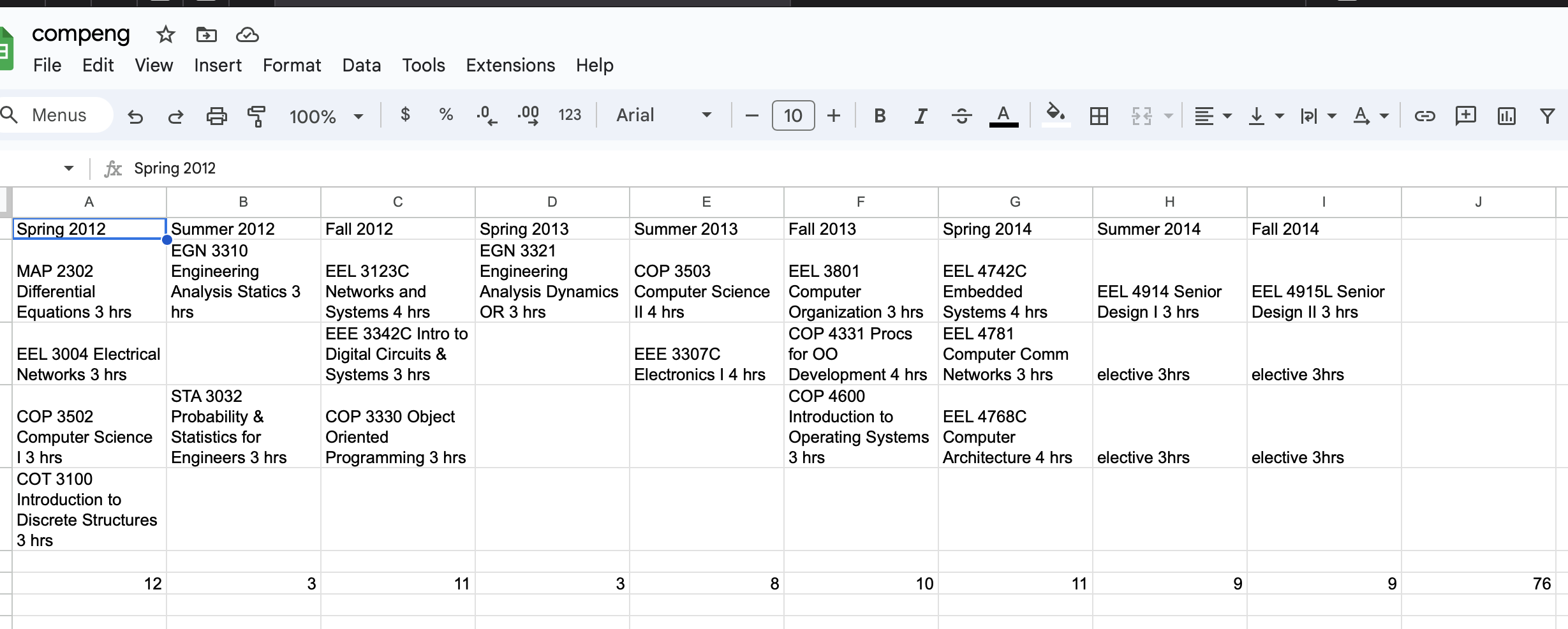
It is hard to believe that I only have 3 classes left to finish up my Masters. One elective (Power Electronics) and Project 1, 2. Going to stretch it out over 2024 and really try and present an impressive project as my capstone. I think this maybe where my university education ends.
So if you aren’t aware. I am now a YouTube star…
I am really proud of the work the team of students did. I was team lead and guided the team on creating a fairly extensive software suite for the Ghost Robotic’s dog. We only had about 9 weeks for the challenge and what we have presented is quite impressive. Android Application, ROS2 Node, Threat Detection in OpenCV and Python. It runs the gamut.
Will be up to the AFRL in 2024 to see if we build off this knowledge/team. Looking forward to the follow-up.
Python Again
So with all the hype in the world around AI and Deep Learning I finally decided to dig back in. I took Machine Learning in Fall of 2022, but this was very much the “old” machine learning. Meaning. Linear Algebra review, Support Vector Machines, etc. So I’ve enrolled in Andrew Ng’s Deep Learning Course: https://www.coursera.org/specializations/deep-learning?
This is excellent course and I’m 2/5 of the way through it now. The first class is “easy” because I’m familiar with it a bit. But the second was quite the slog and I had to really study and take time. I’m going to take a few more weeks before I start on the convolutional neural networks and then I’m excited to get to sequence models. I don’t think it gets to the transformer architecture in this course, but it should be good platform to learn the new hotness (ChatGPT etc)
I’m trying to switch all programming projects that make sense to python. To keep everything straight. To give myself a refresher, as I’ve not done python really for serious projects since Python2. I’ve decided to enroll in ExecuteProgram.com’s python course which is quite good. Almost done with it: https://www.executeprogram.com/courses/python-for-programmers/lessons/wrapping-functions (edit: now done with it 12/29/2023 in perpetual review?)
Very impressed with the method Gary uses at Execute Program. Looking forward to the next class he will release which will deal more with classes and advanced python stuff.
That being said the current non-work programming task I’m working on is… https://devtalk.com/books/the-ray-tracer-challenge which I’m writing in python and hope to have some pictures rendering in 2024. Wish me luck.
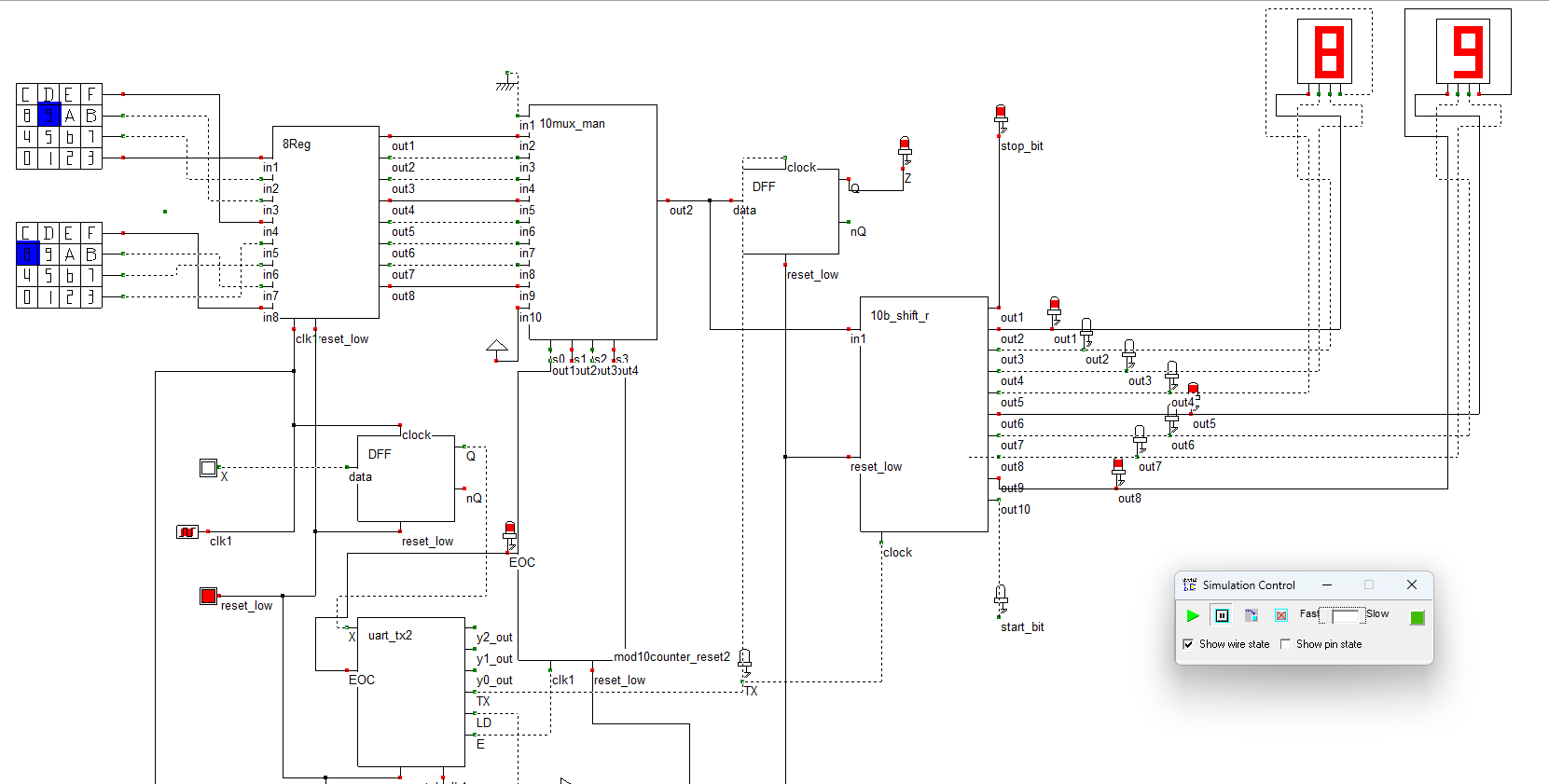
Finished up the semester a few weeks ago now and am recovering from the sprint of creating a UART transmitter in VLSI class. The software was quite buggy and old, but it ended up working.
It was quite fun designing everything from scratch with NPN and PNP transistors. I actually punted on laying this beast out by hand. I did do some layouts by hand though…
I also wrote a paper and a bit skeptical including it in the public, but was a solid week of work. I actually used Word for this instead of LaTeX, because life is too short. My undergrad self would be disappointed. Professor gave me a ninety on it, no notes back 😦
This next semester is Aerial Robotics and some cyber security class. Looking forward to finishing the year and starting on the capstone project for my masters.
Over the past month or two I’ve also been involved with a robotic dog project. Learning ROS2 and fighting with simulators and docker. I’ll post more when there is something. Here is a short video of it walking some way points.
About halfway done with this ROS2 book. Is very good, love that it is in color. GUS pictured above with lidar and thermal cameras
Finally my guitar pedal addiction has been traded for eurorack.
Spending it as fast as I’m making it. Living the dream. See you next time!
Software companies and drug dealers both call their customers the same thing. Users.
unknown
Forced Upgrades (with no functional benefit/change)
Requiring Network or Lookup on Network on startup
Telemetry
Dependencies
Blackholes
Of the above, I think the forced upgrades is the worst. Like most things in the list, they make developers lives easier, but it is terrible for the customer.
Shipping often has become an ethos, but I’m afraid that most of your users would rather stability over new releases. I look at software the same way I look at restaurants. I want the same burger I got last time. I may glance at the specials and think maybe I will try that another time.
If they really were so special, they’d be on the menu
Seinfeld
If they really were so special, they’d be on the menu, to quote Mr. Seinfeld. It is quite disturbing to my flow of actually getting work done to launch an app and be presented with a question if I’d like to upgrade. No, I’d actually like to do the thing I started the app for. Edit the file. Get off my lawn.
Not sure if it is to justify the developers own existence, but to me, more versions signal more problems. Once a quarter should be enough. Pushing betas out to users and letting them test it for you is lazy. Be your own first user and find the rough edges first.
I’ll just end with the concept of a Blackhole. Features like inboxes, random feeds, etc that only serve to boost engagement are the death of product.
Please click next page to continue reading…
The image in this post is: By Ute Kraus, Physics education group Kraus, Universität Hildesheim, Space Time Travel, (background image of the milky way: Axel Mellinger) - Gallery of Space Time Travel, CC BY-SA 2.5, https://commons.wikimedia.org/w/index.php?curid=370240