If it isn’t clear I have a GPU addiction. This post will render away all doubt about my technolust. I love hardware. I love exotic hardware that I’ve never seen before. I love to program or configure directly against this hardware to squeeze every last bit of performance out of it. Think how some (even old) XBox or Playstation games still are amazing on the platform that is a decade old. They programmed down to the metal.

>>> tell the story of saddam huessein and the playstation super computer he built
Saddam Hussein, the former President of Iraq, was known for many things, but building a PlayStation “supercomputer” is not one of them. There have been rumors and conspiracy theories that Hussein’s regime had developed a powerful gaming console-based computer for military purposes, but these claims have been widely debunked.
The story likely originated from a 2000 article in the Iraqi newspaper Al-Nasiriya Al-Gadida, which claimed that Iraqi scientists had built a supercomputer using 3,000 PlayStation 2 consoles. The computer was said to be used for weather forecasting and oil exploration, not military applications. However, there is no evidence that such a machine ever existed, and the claim has been dismissed as propaganda by many experts.
It’s worth noting that while the PlayStation 2 did have impressive technical specifications for its time, it was not designed to function as a supercomputer. Building a true supercomputer requires specialized hardware and software, as well as a deep understanding of computer science and engineering principles. It is highly unlikely that such a machine could be built using off-the-shelf gaming consoles.
In summary, while Saddam Hussein was known for his military ambitions and authoritarian rule, there is no evidence to support the claim that he built a supercomputer using PlayStation consoles. The story appears to have been exaggerated or fabricated for propaganda purposes.
Mixtral24
I guess I’ve been snoped. Moving on. If you want ME to build a super computer out of playstation2’s let me know.
Building a Better Large Language Model System
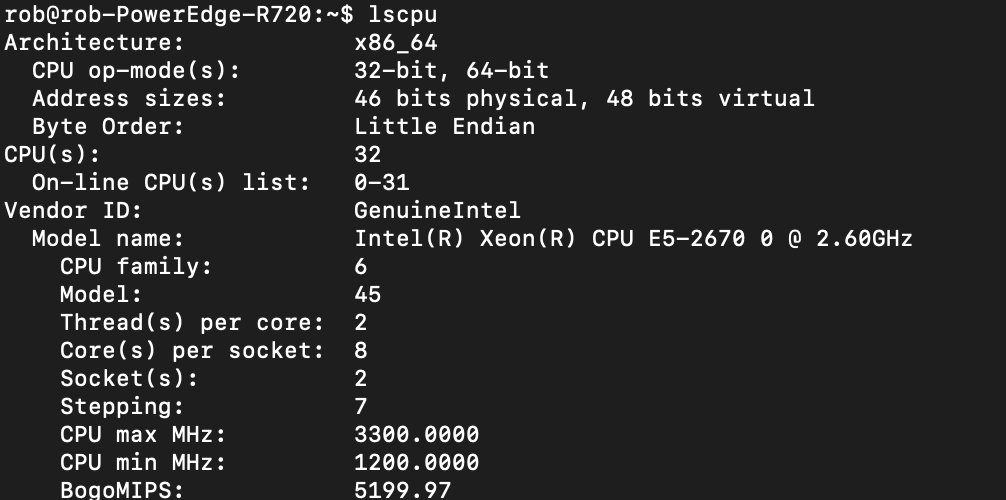
If you have been following along, I have a consumer level machine learning rig and a Poweredge r720. Things are going great but I figured I’d work my way towards the newer GPUs for servers. I needed a new server and, why not let’s try the r730. It is a little more expensive on e-bay but it looks a bit better spec wise in some areas I find desirable.
What area’s are those?
>>> what is difference from a PCIe bus between a r720 and an r730?
Both the Dell PowerEdge R720 and R730 servers use Peripheral Component Interconnect Express (PCIe) slots to connect various expansion cards, such as graphics cards, network interface cards, and storage controllers. However, there are some differences in the PCIe bus architecture between these two server models.
The Dell PowerEdge R720 supports up to eight PCIe 3.0 slots with a maximum bandwidth of 8 GT/s per lane. The server has a total of 40 PCIe lanes available for expansion cards. The R720 also supports the use of mezzanine cards, which are smaller expansion cards that can be mounted directly onto the motherboard.
On the other hand, the Dell PowerEdge R730 supports up to twelve PCIe 3.0 slots with a maximum bandwidth of 8 GT/s per lane. The server has a total of 64 PCIe lanes available for expansion cards. The R730 also introduces support for PCIe Gen 3 x16 slot, which provides higher bandwidth than the previous generation.
In summary, while both servers use PCIe 3.0 slots with similar maximum bandwidth per lane, the R730 supports more PCIe lanes and slots compared to the R720. Additionally, the R730 introduces support for a higher bandwidth PCIe Gen 3 x16 slot, which is not available on the R720. These differences can affect the overall performance and expandability of the server depending on the specific workload requirements and expansion cards being used.
Mixtral24
Poweredge R730
- Really struggled this time to get ollama, you can see in the history (setup) below
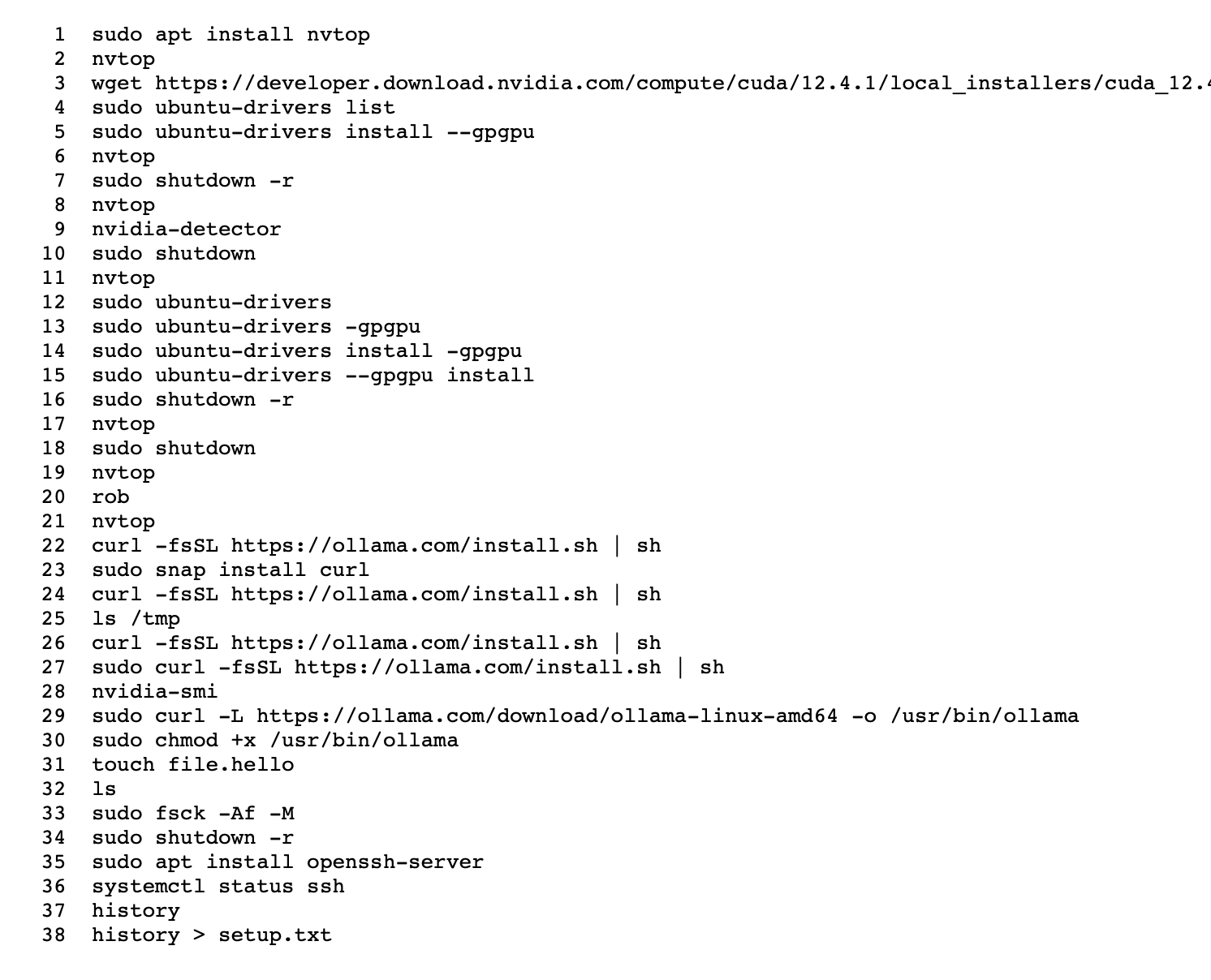
this is all you should need. starting point: fresh kubuntu install.
- sudo apt install nvtop
- nvtop # you will see no gpus probably
- sudo ubuntu-drivers –gpgpu install
- sudo shutdown -r
- …
- nvtop # hopefully you see gpus!
- # install ollama (hopefully seemless for you)
- # looking at vllm next
Nvidia Tesla T40 16gb
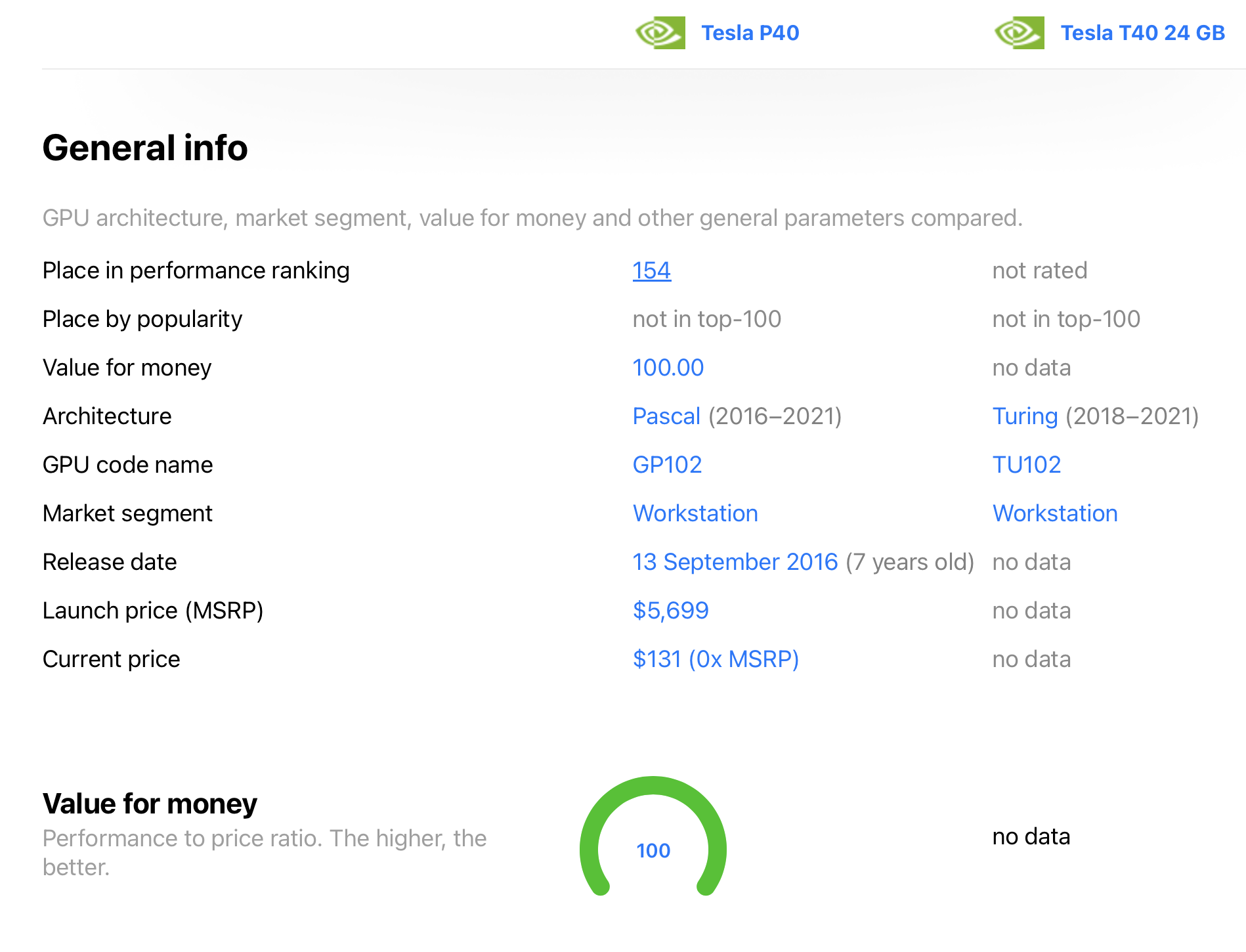
I’m spending more than i’d like on these but I think the power savings will be worth it in the “Total Cost of Ownership” (TCO). Take a look:

It is amazing the size difference these two GPUs:


Rob Web Services
- idle machines make me sad
- soon, shoot me email/dm/tweet.